概念
“模型蒸馏”(Model Distillation)是一种高效的模型压缩与知识转移方法,其通常会使用一个已经经过训练的教师模型,该模型在大型数据集上表现出色。然后,将教师模型的知识传递给一个更小的学生模型,使得学生模型能够以较小的规模进行推理,并保持与教师模型相似的性能。
教师模型
教师模型是指一个已经训练好的、容量大、性能强的模型。它的作用是在蒸馏过程中提供预测概率(soft label),指导学生模型的学习。
为什么蒸馏比直接训练小模型效果好?
| 标签(Hard Label) | 教师模型预测(Soft Label) |
|---|---|
| 猫 = 1,狗 / 兔 = 0 | 猫 = 0.87,狗 = 0.1,兔 = 0.03 |
标签只能获取“正确答案”,而教师模型的预测分布能够获取错误选项的相似程度,也就是更丰富的“知识结构”。通过Soft Label学生模型能够学习到更细腻的类间关系。
以蒸馏知识来源分类
此外,从蒸馏知识来源可以将模型蒸馏分为3类:Logit-based, Feature-based 以及 Similarity-based。
Logit-based: Logit Value是模型最后一层的输出,其目的是迫使学生模型模仿教师的最终预测,这些预测应该包含教师的有用“Dark Knowledge”(Hinton,2015),由于使用最后一层的预测,所以可以适应多种任务。
Feature-based: DNN能够在其各层提取不同层次的特征,而这些特征来自网络中间层的多层次表示,其能够成为学生模型学习知识的来源,并且这些中间表示提供了逐步引导至最终预测的隐层信息。
Similarity-based: 相似性蒸馏通过提取模型中隐层结构化知识和关系,来引导学生模型,其目的是让学生模型的隐层表达更接近于教师模型。
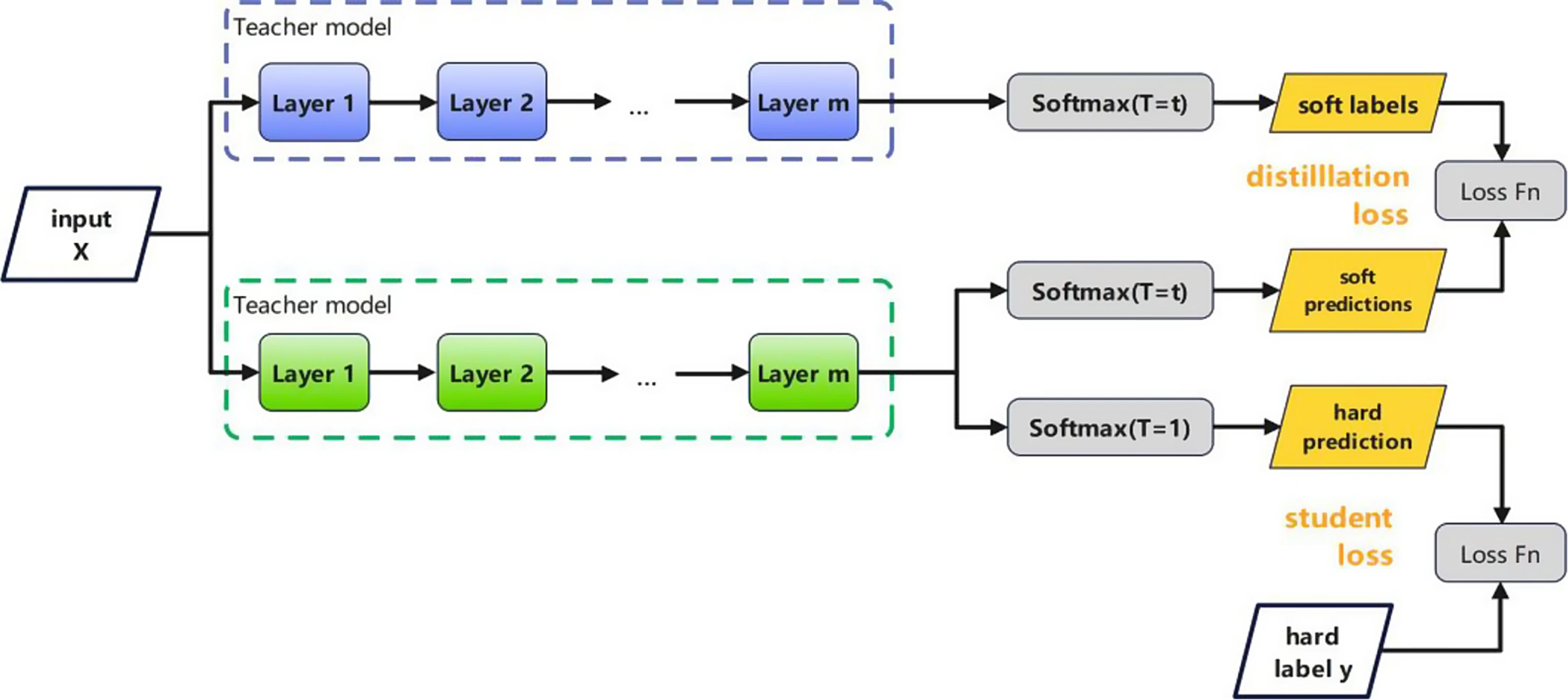
知识蒸馏 (Knowledge Distillation, KD)
\(q_i=\frac{exp(z_i/T)}{\sum_jexp(z_j/T)}\)
知识蒸馏是Hinton等人于2015年首次提出:
- 首先对Softmax计算方式进行改变引入了参数T (Temperature),T越高时各类别的概率越平滑,温度参数T的作用可参考-知识蒸馏中的温度参数 T(Temperature)的作用;
- 之后通过训练一个教师模型以得到软标签 (Soft Labels),该教师模型的计算复杂度较高;
- 最后在学生模型上计算概率分布,其Softmax在对于真实标签时T=1,在对于软标签时T与教师模型一致;
- 使用学生模型预测 (Hard Prediction) 与软标签计算KL散度损失,再与真实标签 (Hard Label) 计算交叉熵损失,得到硬标签与软标签两个损失值。其中,软标签损失鼓励学生模型模仿教师模型的输出概率分布,硬标签损失则鼓励学生模型正确预测真实标签。
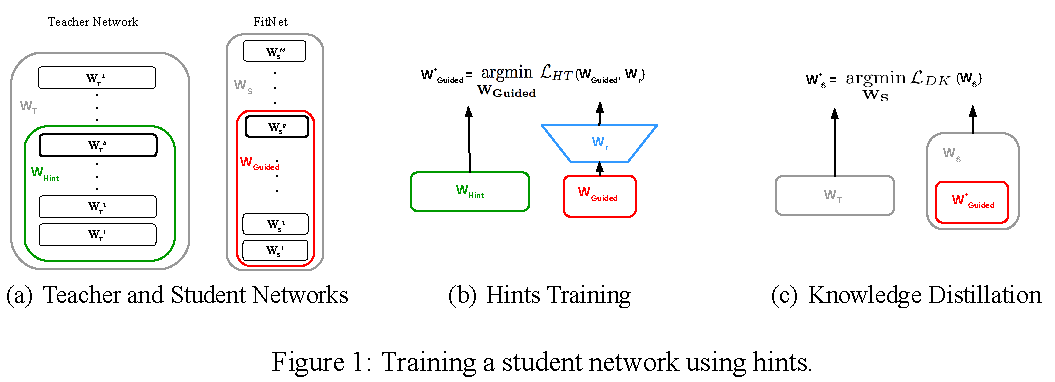
中间层蒸馏 (Intermediate Layer Distillation)
Romero等人2015年提出了FitNets,该模型不仅利用教师网络最后的输出 logits ,还利用了它的中间隐层参数值 (Intermediate Representations) 来训练学生网络。
\(\mathcal{L}_{HT}(\mathbf{W_{Guided}},\mathbf{W_r})=\frac{1}{2}||u_h(\mathbf{x};\mathbf{W_{Hint}})-r(v_g(\mathbf{x};\mathbf{W_{Guided}});\mathbf{W_r})||^2\)
为了让更细更深的学生网络获得更好的训练效果,那么作者认为不局限于模型输出,在模型中间教师模型也可以对学生模型进行提示,而在中间维教师特征与学生特征可能不一致,因此直接引入regressor改变学生特征纬度然后进行损失计算,该部分被称为 Hints Training ,同时为了不增加计算量,作者使用conv卷积层保证教师模型和学生模型中间层的输出纬度一致。
且最终通过对于Hint与Guided层输出特征计算损失,以此拉近教师模型与学生模型中间隐层间的距离。
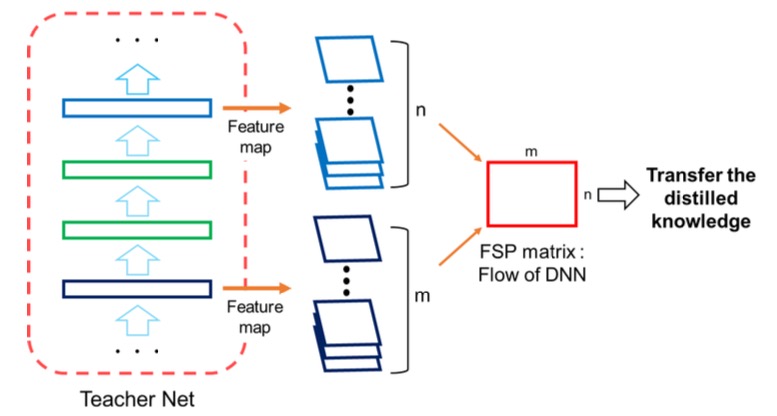
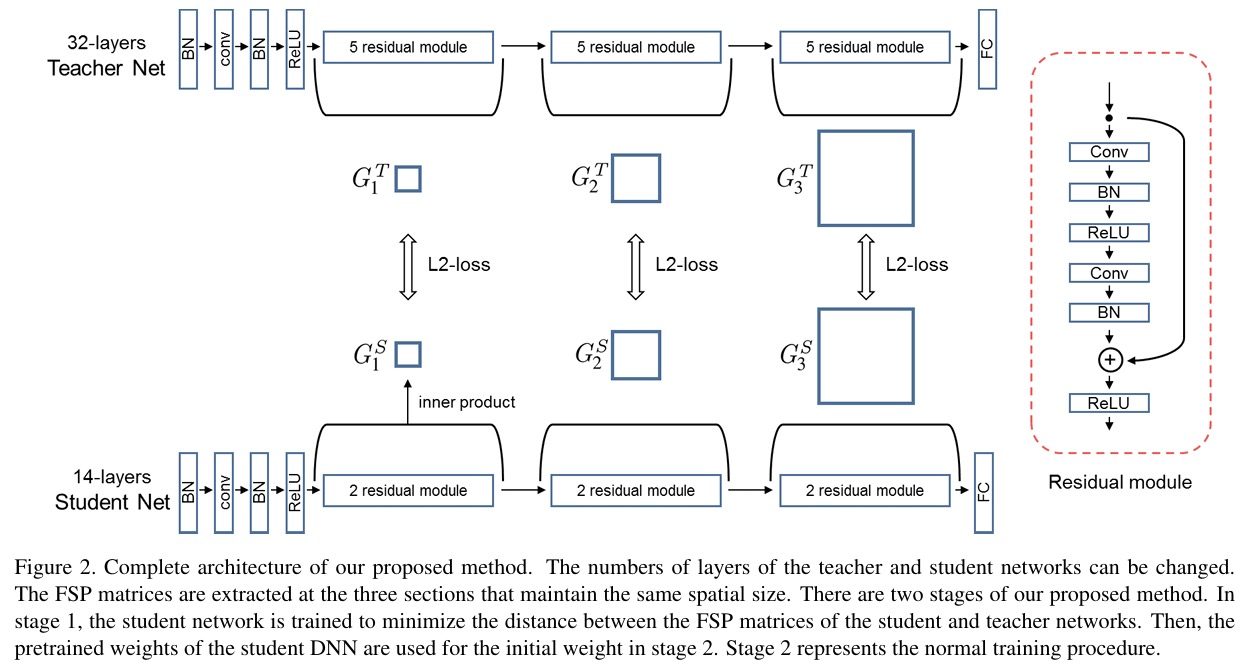
隐层信息蒸馏 (the Flow of Solution Procedure, FSP)
\( G_{i,j}(x;W)=\sum_{s=1}^h\sum_{t=1}^w\frac{F_{s,t,i}^1(x;W)\times F_{s,t,j}^2(x;W)}{h\times w} \)
HintNets将网络中间层的输出作为教师信息传递给学生模型进行学习,然而在遇到实际问题时学生模型应该学习到的是“解决问题的方法”而不是“解决问题的答案”,因此Yim提出了一个FSP (the Flow of Solution Procedure, FSP) 矩阵,该矩阵通过计算教师模型中某一模块Block的首层与末层的特征图的内积(或相邻层的特征图,那么获取到的则是该部分的隐层信息),以此得到该block的隐层信息。由于用于生成FSP的两层特征图除通道数外结构应保持一致,所以若两层的特征图结构不一致,则使用最大池化操作保持一致。
\( \begin{aligned}
& L_{FSP}(W_t,W_s) \\
& =\frac{1}{N}\sum_x\sum_{i=1}^n\lambda_i\times\|(G_i^T(x;W_t)-G_i^S(x;W_s)\|_2^2
\end{aligned} \)
由于网络结构等原因,网络在一些位置的spatial size发生变化,所以选择教师网络和学生网络对应位置具有相同spatial size的特征图来生成FSP矩阵。之后,计算教师网络与学生网络对应的FSP矩阵间的L2损失。
[1] Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network[J]. arXiv preprint arXiv:1503.02531, 2015.
[2] Romero A, Ballas N, Kahou S E, et al. FitNets: hints for thin deep nets (2014)[J]. arXiv preprint arXiv:1412.6550, 2014, 3.
[3] Yim J, Joo D, Bae J, et al. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4133-4141.
以模型蒸馏方式分类
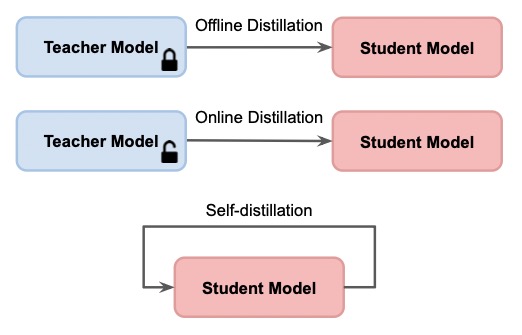
从模型蒸馏方式,可以将其分为3类:Offline Distillation, Online distillation 以及 self-distillation。
Offline Distillation: offline蒸馏方式为当前大多模型蒸馏所选方式,其首先通过训练一个大型预训练的教师模型,然后再将教师模型的知识蒸馏到学生模型上,其包含2个Stage,前文所描述的3种蒸馏方式均为Offline Distillation。
Online distillation: online方式则是教师模型和学生模型同时训练,即整个蒸馏只包含1个Stage。
Self-distillation: 该方法则是教师模型和学生模型为同一个网络,也只包含1个Stage。
Offline distillation
前文提到的3种蒸馏方式均为Offline蒸馏,其预训练了一个大型的教师模型,并将该预训练模型的知识蒸馏到学生模型中,其包含两个Stage,1个是训练教师模型并固定参数,另1个是训练学生模型。
Online distillation: Online Knowledge Distillation with Diverse peers (OKDDip)
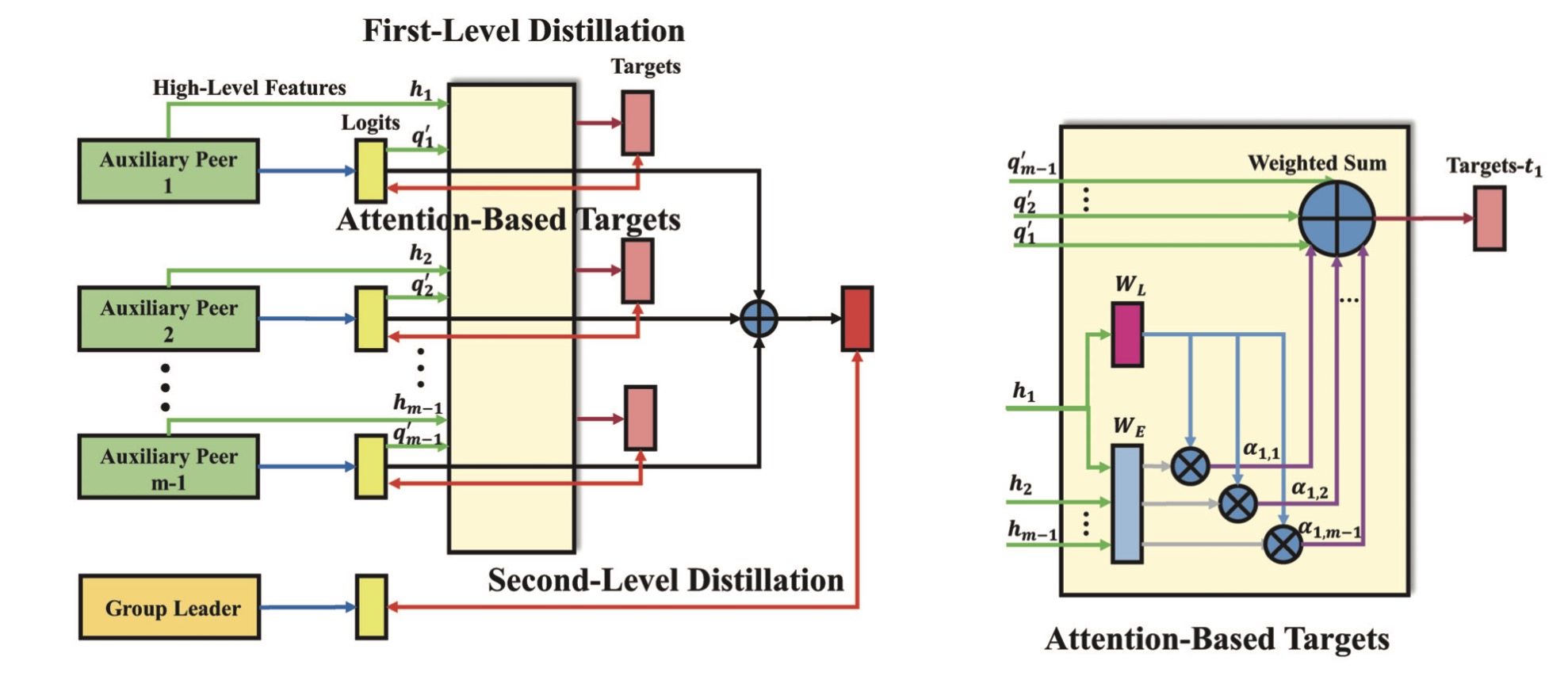
对于Online蒸馏方法,其可以通过使用多个学生模型的聚合中间预测作为目标来训练每一个学生模型,OKDDip方法通过两次蒸馏实现,其先提出一组peers来学习peers间的信息并进行第一轮蒸馏得到Soft Labels,之后再使用该Label对Group Leader进行第二轮蒸馏。
\(\alpha_{ab}=\frac{e^{L(\boldsymbol{h}_a)^TE(\boldsymbol{h}_b)}}{\sum_{f=1}^{m-1}e^{L(\boldsymbol{h}_a)^TE(\boldsymbol{h}_f)}},\boldsymbol{t}_{a}=\sum_{b=1}^{m-1}\alpha_{ab}\cdot\boldsymbol{q}_{b}^{\prime},\mathcal{L}_{dis1}=\sum_{a=1}^{m-1}KL(\boldsymbol{t}_a,\boldsymbol{q}_a^{\prime}).\)
其在第一轮蒸馏时,使用各个peer的特征与概率分布进行自注意力计算得到α阈值,再与各peer概率分布相乘求和得到soft target,最后进行KL散度的计算得到第一轮蒸馏的损失值。
\(\mathcal{L}_{dis2}=KL(\boldsymbol{t}_{m},\boldsymbol{q}_{m}^{\prime}),\mathcal{L}_{OKDDip}=\sum_{a=1}^m\mathcal{L}_{gt}(a)+T^2\mathcal{L}_{dis1}+T^2\mathcal{L}_{dis2}.\)
之后,对所有peer的soft label求平均得到整体的soft label,再与Group Leader进行第二轮蒸馏得到第二轮损失,最后加上交叉熵损失得到最终损失值。
Self-distillation: Be Your Own Teacher
Self-distillation是在线蒸馏的一种特殊形式,其教师模型和学生模型为同一个模型。
在本项工作中,为了在不提升计算成本的情况下提升模型的准确性,作者提出并使用了一种自蒸馏技术。从整体上看,该方法是使用深层的block作为软标签将其知识蒸馏到渐层的block上。在训练时增加了Bottleneck, FC layer 以及 Softmax 这些模块以实现蒸馏,最终在推理阶段不需要这些模块,所以未增加模型参数。
\(\begin{aligned}
loss & =\sum_i^Closs_i \\
& =\sum_{i}^{C}\Big((1-\alpha)\cdot CrossEntropy(q^{i},y) \\
& + \alpha\cdot KL(q^{i},q^{C})+\lambda\cdot||F_{i}-F_{C}||_{2}^{2}\Big)
\end{aligned}\)
整体上一共使用了3种损失:
- 灰色路线:前文提到的中间层蒸馏,使用从ResBlock出来经过Bottleneck的特征图,计算深层特征图与渐层特征图之间的L2损失
- 蓝色路线:图标里作者标错了,不是from labels是前文提到的知识蒸馏中的from distillation,其使用深层和渐层的softmax输出计算得到Distillation损失(KL散度)
- 绿色路线:该部分为from labels,计算每层输出的标签与真实标签的交叉熵损失
[4] Chen D, Mei J P, Wang C, et al. Online knowledge distillation with diverse peers[C]//Proceedings of the AAAI conference on artificial intelligence. 2020, 34(04): 3430-3437.
[5] Zhang L, Song J, Gao A, et al. Be your own teacher: Improve the performance of convolutional neural networks via self distillation[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 3713-3722.
感谢浏览,欢迎关注祁彧w博客!

文章评论