本文总结了 XAI 人工智能可解释性综述文章“Interpreting Black‑Box Models: A Review on Explainable Artificial Intelligenc”,包括XAI相关概念、XAI需要什么、XAI框架以及可解释验证方法。
本文目录
Abstract
当前大多数机器学习(Machine Learning, ML)模型和深度学习(Deep Learning, DL)模型由于其结构复杂缺乏对决策过程的可解释,导致这些模型被称为“Black-Box”。而这些模型当被用于某些关键领域时,例如银行、网上贸易、医疗以及公共服务及安全领域,对其决策基础很难被解释,以至其较难被应用。所以对其学习过程及决策过程进行解释,是为模型提供透明性及决策可理解性的基础。然而,当前研究对发现模型内部决策流依然是困难和低效率的。
本文通过选择分析当前最新XAI(Explainable Artificial Intelligence, XAI)模型总结了XAI的发展,同时提供了对于XAI框架的理解以及深度验证,以及XAI在应用中的效率。
本文的贡献:
1、本文提供了一个完整的层次分类,为之后XAI的研究者提供了基石。
2、我们使用该领域当前的流行方法,着重于XAI及其影响的最新发现。
Fundamental Concepts of XAI
Black-Box Model
黑盒模型是指其是不透明系统运行的机器学习模型,同时其模型内部的工作原理不易访问或理解。
这类模型基于输入数据提供预测结果,然而其决策背后的过程和原因对使用者来说是不透明的。
透明性的缺乏使得其对于用户来说存在诸多问题:
1、用户很难理解模型的行为;
2、较难检测发掘潜在的偏差和错误;
3、模型不易解释其决策的依据。
Types of Interpretability
可解释能力可以作为人类理解或预见机器学习模型预测结果的一种程度。
Tjoa et al.[1] 等人将可解释能力分为两类
1、可感知的可解释性
该类的可解释通常通过提供可视化证据进行解释,但是由于黑盒算法仍然存在于其内部,所以其并未真正的解释XAI模型内在的决策动机。此外,也可以通过显著性特征来进行解释,其通过关联所有输入特征对于决策的重要性来进行解释,包括LIME[2]、ACE算法[3]以及CAM[4]等热力图的形式。
2、基于数学结构的可解释性
基于数学结构的可解释性,通过数学算法统一了所有的可解释性,其揭示了神经网络算法更深层次(存储了大量复杂信息)的数学机理。例如,TCAV[5]通过概念激活向量量化了用户定义的概念对于预测的重要性。此外,t-SNE和SVCCA方法[6]通过引导输入子空间进行无错误预测。
Interaction of Explainability With AI
可解释能力对于AI系统的应用来说越来越重要,尤其是在关键领域例如医疗、金融以及刑事司法等。
以下可解释能力在多个方面影响着AI系统:
1、模型可解释能力,意味着模型的决策过着可以被用户理解以及解释。
2、监管需求,在一些关键领域,AI系统被监管要求能够被解释,以此确保其透明性以及可理解性。
3、信任及采纳,可解释性可以在建立对人工智能系统的信任方面发挥作用,这对于人工智能系统的广泛采用和使用至关重要。
4、模型验证,可解释能力能够帮助验证AI模型所作出的决策,同时确保其不包含偏差及错误信息。
5、调试和改进,可解释性可以深入了解人工智能模型如何做出决策,从而更容易识别和解决错误或偏见的来源。
Need For XAI
Fair and Ethical Decision Making
人工智能伦理,是一套通过某种方式指导什么是对的、什么是错的、什么是好的、什么是坏的的一套原则。现有的XAI研究主要集中在技术问题上,但更希望有一个研究分支来处理权衡问题和伦理问题。
以下有一些方法来实现算法的公平性:
1、反事实(Counterfactuals),这是阐明人工智能和理解算法公平性的广受欢迎的策略。反事实的一个出色应用是风险管理。
2、代理公平方法(Proxy fairness methods),这些方法使用代理(例如人口统计信息)来纠正人工智能系统中的偏见。
3、通过意识实现公平(Fairness through awareness),这种方法通过使用专门设计用于捕捉有助于实现公平和道德考量的相关因素的数据,来训练人工智能模型。这有助于确保模型产生公平和道德的结果。
4、公平性约束(Fairness constraints),公平性约束是公平性标准的数学公式,可用于优化人工智能模型。例如,公平性约束可用于确保人工智能模型不会歧视某些人口群体。
5、人机交互方式(Human-in-the-loop approaches),人机交互方法涉及将人类监督纳入人工智能系统的决策过程。
XAI Evaluation Framework
Design Principles For Interactive XAI
自 XAI 出现以来,研究人员一直试图解决解释黑盒模型所涉及的过程的多学科性质。为了在这一领域取得持续进步,提倡采用多学科的方法,包括来自各个独立研究领域的协作努力。此外,一个决定性因素是坚持多个利益相关者的需求和利益:设计师、决策者以及最终消费者。鉴于当前的研究发展,当务之急是寻求一种更正式、更全面的程序标准来解释不透明的人工智能算法。因此,建议在人工智能设计和部署工作流程中集成和应用解释时遵循以下主要原则:
Adeptness to the User Behavior
XAI 的有效性取决于它给用户带来的与 AI 交互的动机程度。Zhu 等人[7]注意到,当前大多数研究并没有关注XAI 实践的实用性和有效性,而是提出了新的解释方法。因此,承认用户行为的重要性将有助于 XAI 模型更好地利用其功能和参数来解释黑盒模型。
Collaborative Techniques Should Be Implemented More
以人为本的设计原则被视为一种宝贵的资源,有助于开发具有上下文价值的解释。开发人员应致力于让用户参与开发过程的早期阶段,这将确保他们的积极参与。让用户能够自我解释人工智能算法中涉及的逻辑有助于使 XAI 模型更加合理和实用。
Collaborative Techniques Should Be Implemented More
理想的解释是融合了多个知识领域的专业知识。哲学、心理学和认知科学等人机交互(HCI)技能已经通过开发能够刺激人类解释过程的解释,证明了它们在可解释人工智能领域的价值。必须阐明某些模型不可知论方法如何结合全局和局部的可解释性范围来强化可解释人工智能模型的目标。
Explanations Have More Dimensions Than Just Performance
适当评估解释方法的能力不仅是确定它们是否有效。由于生成的每个解释都有其自身的影响,因此应根据定性绩效(满意度、信任和理解)、最终任务的完成、缓解和错误分析等维度对其进行评估。设计师应该致力于开发一个可以衡量解释定性和定量能力的评估基准。应该鼓励以目标为中心的解释,这将使设计师能够预先决定解释将对人工智能算法产生什么影响
Contradictions Provide Alternative Approaches
矛盾和反事实的运用被称为 XAI 设计师在开发过程中需要涉及的最佳实践之一。此陈述的一个例子是基于 AI 的医疗诊断系统的开发[8]。在设计过程中利用矛盾和反事实可以帮助确保诊断系统能够识别和处理罕见或不寻常的病例,这在医学诊断中至关重要。例如,通过向系统提供具有相似症状但诊断不同的患者的反事实示例,系统可以学会识别区分一种诊断与另一种诊断的独特特征。此外,通过向系统展示相同症状可能指示不同疾病的矛盾示例,系统可以学会评估多种可能性并做出更准确的诊断[9]。这可以增加对系统诊断的信任并改善患者的治疗效果。除了提供有关系统限制条件的宝贵知识外,它们还有助于发现其漏洞。
Are Explanations Always Important?
本着整体论的精神,Bunt 等人[10]最初在他们的工作中提出这个问题,主要是因为在为用户提供低成本决策的系统中部署的解释技术非常有效。他们发现,尽管这些系统不透明,并且没有提供预测背后的推理,但用户仍然对它们有积极的看法。因此,提出了一个重要的问题:“获得解释的成本是否超过其收益?”
Amendments Go a Long Way
迄今为止,XAI 被认为是技术领域的一个新概念。随着越来越多的研究,获得的经验将有助于改变人们的信念。因此,至关重要的是要理解,生成解释的过程永远不是“一次性的”。特别是从动态环境的角度来看,不断增加的用户数量和修改后的解释最终将推动可解释性的最新发展。解决诸如“修改如何影响算法”和“为什么我应该考虑这个解释而不是以前的解释”等问题将确保积极的反馈,并将使 XAI 设计者受益,因为他们与用户进行了长期互动。因此,除了坚实的基础之外,必要的修改总是有助于在 XAI 的结构中增加更多内容,这将产生更大的影响 。
总而言之,本文总结了一系列针对可解释系统设计和开发的设计原则。然而,仅仅制定一些指导方针并不一定能保证成功。虽然一些原则的实施正在进行中,但有些原则也没有取得任何进展。XAI 设计者表示,为了在可解释性方面得出强有力的结论,需要进行严格的研究和测试,并辅以合理的证据和相关的工作背景。
Techniques For XAI Implementation
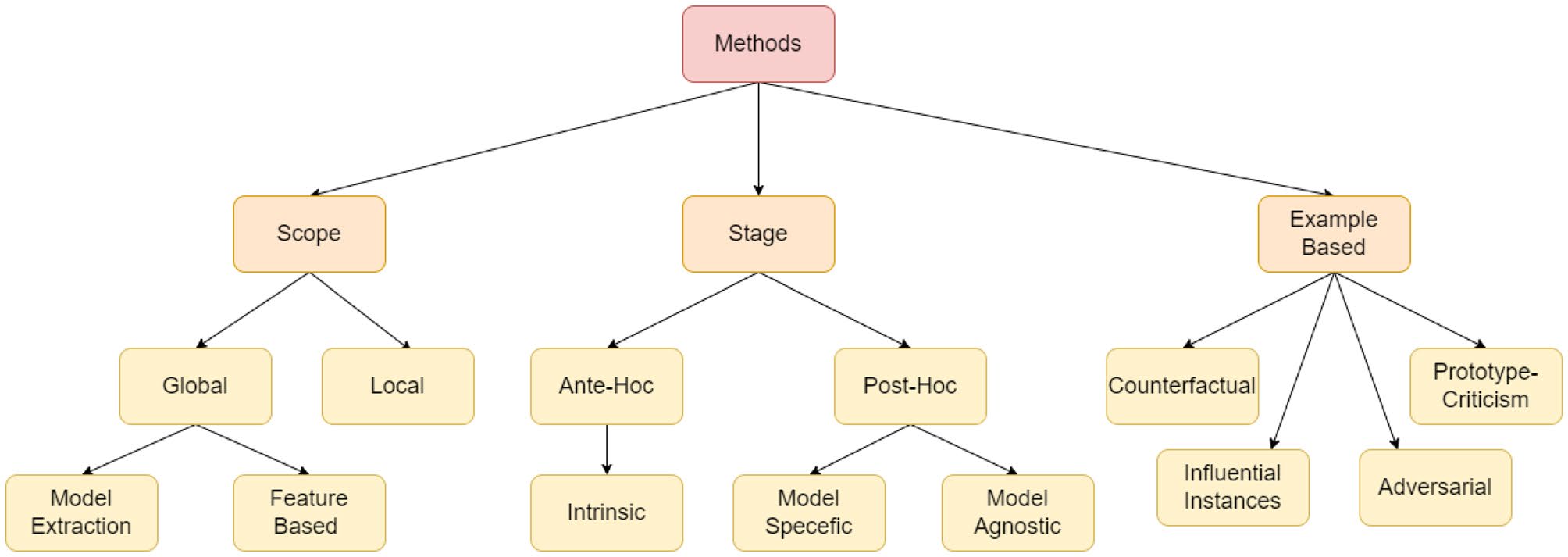
在为典型的 ML 模型设计解释方法时,该方法需要回答一些基本问题:为什么模型会产生这种预测,以及模型决策背后的逻辑和推理是什么?然而,随着不断进步,研究人员遇到了其他问题,这些问题无法通过当前的解释方法设计来回答。因此,设计了不同类型的解释来满足不同行为、问题和用户类型的目的。由于典型的最终用户专注于特定案例(局部)的兴趣,而领域专家需要对 AI 预测有充分的了解(全局),因此可解释性方法需要在其解释中详尽无遗。
值得注意的是,XAI 中的大部分前期工作都是从解释者的角度完成的,例如,能够理解 AI 预测的工作原理及其背后使用的逻辑的领域专家。相反,为被解释者(例如最终用户)提供令人满意的解释的方法却很少见。这种对详尽解释的阻碍源于这样一个事实:目前在开发 AI 模型领域工作的领域专家也是开发 XAI 对应模型的人。因此,他们在 XAI 方面的工作很少涉及对被解释者的关注。
因此,正如我们的框架所建议的,在设计和开发 XAI 模型时,牢记最终用户非常重要。根据我们对文献进行的调查,我们提出了对所有类型的解释进行分类,旨在解释黑盒算法的逻辑。如图2所示,方法的总体结构。
Based on Scope
从范围上看,可解释性存在两个研究方向:1、通过考虑模型所有解释的整体视图,即全局解释;2、通过考虑模型提供的解释的个别样例,即局部解释。
Global
全局可解释方法旨在使人们更容易理解模型的总体逻辑,以及用于产生特定预测的完整原因。这些全局性策略经常有助于大规模决策,例如药物使用或气候变化,因为它们专注于为所有潜在情景编制解释。
我们将实现全局可解释性的各种方法分为以下子类:
1、Model Extraction
为了正确模仿黑盒模型的判断,模型提取需要根据黑盒模型的预测,来训练一个可解释的模型(例如线性模型或决策树)。全局替代模型是此过程生成的模型的另一个名称。以下是创建全局替代模型所需的步骤:
- 选择一个理想的数据集 X,它可以是同一个黑盒模型的训练数据集,也可以是全新的原始百分比分布的数据集。
- 训练后的黑盒模型根据所选数据集生成预测。
- 为了符合黑盒模型的预测,选择一个可解释的模型并在数据集 X 上进行训练。
其中,规则提取和模型蒸馏是创建模型提取算法时主要使用的两种策略。
规则提取:通过一定方式抽取模型的决策逻辑规则,以表示模型的决策过程
模型蒸馏:通过将复杂模型中的隐层知识转移至更为透明和可解释的简单模型上,以此为模型决策提供解释。
Rule Extraction 规则提取
1994年Craven[11]提出了一种规则提取方法,通过反复创建和更新一套适用于 ANN 输入和输出类别的规则,并直到所有目标类别都得到处理,以此提取ANN中的规则。
Ras[12]等人提出了三种模式以提取规则:(1)教学规则提取(pedagogical rule extraction);(2)分解规则提取(decompositional rule extraction);(3)折衷规则提取(eclectic rule extraction)。
Johanson[13]等人使用 G-REX 方法从遗传编程中提取规则。同时,为了分别使用回归树和模糊规则来处理回归和分类问题,作者进一步创建了 G-REX[14]。
Zhou[15]等人提出了神经网络集成规则提取方法(The Rule Extraction from Neural Network Ensemble, REFNE),能够通过使用自适应间隔来防止无意义的离散化。
Biswak[16]等人为了解决分类问题,提出了一种通过逆向工程神经网络进行规则提取的方式(Rule Extraction by Reverse Engineering the Neural Networks,RxREN)。
Model Distillation 模型蒸馏
使用规则提取方式,仅能得到一个包含较小黑盒范畴的一个特定解释器模型。因此,Hinton等人[17]提出了透明模型蒸馏,一种统一的模型提取技术,用于解决上述问题。他们将隐层知识,即将来自复杂不透明模型(教师模型)的隐藏知识转移到更简单(学生)模型上,该模型在预测方面能够与深度模型保持一致,同时更具可解释性。
Tan等人[18]扩展了通过模型蒸馏将复杂的黑盒模型提炼为透明模型(称为 iGAM)的概念,进一部证明了蒸馏是一种获得可解释模型的更有效的方法。
Che等人[19]提出了可解释模仿学习(Interpretable Mimic Learning),这是一种基于模型蒸馏的方法,能够学习可解释的表型特征,从而提供有力的预测。Xu等人[20]开发了一种可视化技术DarkSight,其可以用于对特定数据集上的黑盒模型进行解释,灵感来自暗知识(dark knowledge)的概念。
2、Feature‑Based Methods
尽管模型提取(Model Extraction)成功地为黑盒模型提供了全局解释,但研究人员发现,由于模型复杂性的过度简化,准确性有所降低。因此,需要一种既能提供解释,又能保持所需准确度的方法。为了满足这些需求,进一步探究输入特征在算法中的影响或重要性。因此,基于特征的方法可以进一步的划分为两种方式,以衡量输入特征与决策的相关性:特征重要性(Feature Importance)和特征交融(Feature Interaction)。
Feature Importance 特征重要性
通过计算每个特征对预测的贡献,可以计算出模型的特征重要性。Breiman[21]为随机森林提出的排列特征重要性,其说明了当特征值被打乱时,预测误差增加的程度决定了该特征值的重要性。
Fisher等人[22]通过提出模型类依赖性(特征重要性理论 (MCR) 的模型独立变体)扩展了这一概念。本文介绍了一种模型可解释性方法,该方法具有多种优势。通过同时研究整个模型类,与研究单个模型的方法相比,该方法能够更全面地理解变量与预测之间的关系。这种方法还可以帮助识别在不同模型中始终重要的变量,从而提供更稳健和更可靠的解释。然而,这种方法的一个潜在缺点是它可能在计算上有更高的开销,因为它需要训练和评估多个模型。另一个缺点是该方法可能难以处理复杂模型,尤其是那些具有许多变量或非线性关系的模型。这项可解释性工作的成功取决于特定的环境和应用。对于某些数据集和问题,这种方法可能比其他方法提供更准确和更可靠的解释[23][24]。
Feature Interaction 特征交融
如果 AI 算法基于两个特征进行预测,则一个特征的影响取决于另一个特征的值。而由于各个特征会受到其它特征的未知影响,因此最终的预测不能被描述为这些影响的总和。
Freidman[25]建立了 H 统计量(H-statistic),并发现了一种衡量特征相互作用强度的机制。Friedman 和 Popescu 开发了关于 H 统计量的数学表示[26],用于表示任意两个特征 j 和 k 之间的相互作用。并且整理了观察到的部分依赖 (PD) 函数与分解函数之间的变化,而特征之间没有任何相互作用。
Local
局部可解释性侧重于为每个选择和预测提供单独的解释,而不是提供整个黑盒模型内部复杂机制的详细解释。在这些模型中,每个输入特征都与一个权重相关联,最终预测是通过对输入特征及其相应权重的点积加上偏差项进行计算得出的。这意味着可以通过查看相应的权重轻松确定每个输入特征的重要性。此外,通过保持所有其他特征不变并改变感兴趣的特征,可以了解特定特征的影响。
例如,在线性回归模型中,如果想要了解特定特征对预测输出的影响,可以计算输出相对于该特征的偏导数,并将其解释为该特征一个单位变化时输出的平均变化,同时保持所有其他特征不变。与全局可解释性方法相比,对黑盒模型局部行为进行解释更为容易。然而,局部解释可能并不总是正确的,因为其依赖于黑盒模型。此外,简单的解释比复杂的解释更有用。许多研究提出了许多局部解释技术。
Ribeiro[2]等人提出了LIME方法(the Local Interpretable Model-Agnostic explanation,LIME)。它通过在预测值的附近构建可解释的替代模型来近似模型预测。以下是 LIME 工作原理的简明解释:
-
根据黑盒模型的预测,选择一个需要解释的感兴趣的样例。
-
形成一个由扰动样本组成的新数据集,并从黑盒模型中提取它们各自的预测。
-
根据新样本与感兴趣样例的接近程度对其进行相应的加权。
-
现在,黑盒模型可以通过在扰动数据集上训练的可解释模型,并借助以下方程来解释 [26]:
值得注意的是,LIME 生成的替代模型具有较高的局部保真度,这意味着它们能够准确地表示黑盒模型在特定样例周围局部区域的行为。LIME 的目标是创建一个简单、可解释的模型,模仿黑盒模型在被解释样例附近的行为。通过模仿,LIME 提供了对黑盒模型预测的准确和可靠的解释,且无需深入了解其内部工作原理。LIME 生成的替代模型的局部保真度是它们能够提供有用和可靠的黑盒模型预测解释的关键因素。
同时,LIME作者提出的Anchors[27]对LIME进行了扩展。Anchors是一种使用LIME以更高效和可扩展的方式解释机器学习模型预测的方法。Anchors背后的主要思想是预先计算数据集中样例子集(称为锚点)的解释,然后使用这些解释为其他样例生成解释。这种方法降低了生成解释的计算成本,并使得解释大型复杂模型的预测成为可能。Anchors中对LIME的扩展旨在提供更准确、更高效的机器学习模型解释,同时仍保留原始LIME方法的局部保真度。
此外,Ying等人[28]通过利用与节点和边相关的子图,将更多的注意力放在图神经网络 (GNN) 的可行局部近似上,完全使用有限的信息来解释 GNN 的预测。之后,Lundberg 和 Lee通过引入Shapley值[29],使得局部解释进一步发展,他们利用 Štrumbelj 和 Kononenko[30]提出的工作中提供的初步信息,设计了一组称为期望 Shapley (ES) 值的新值,这些值能够统一和证明用于黑盒模型解释的广泛方法(例如 LIME、DeepLift 和逐层相关性传播(Layer-Wise Relevance Propagation))
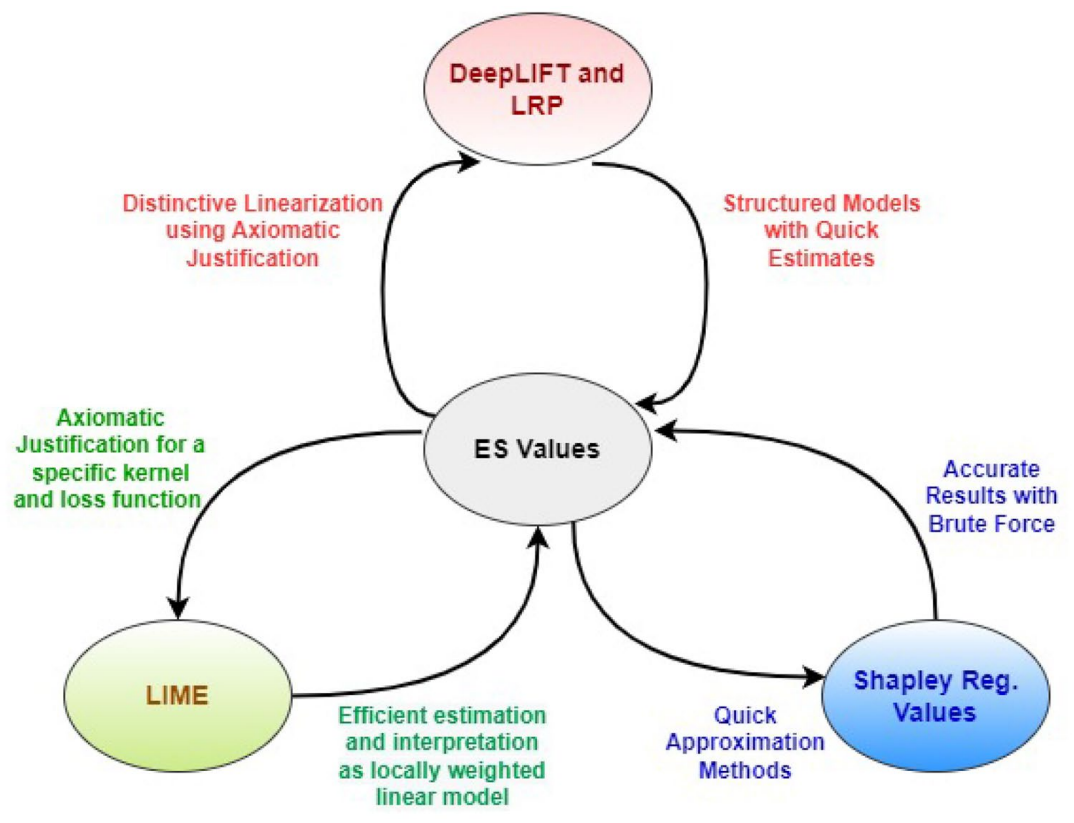
在图3中,箭头表示不同的预测方法如何获得优于 ES 值的优势,反之亦然[29]。
LRP 和 DeepLIFT 符号的组合气泡表明了它们的等价性[31]。
关于局部可解释性,一个值得注意的有趣特征是,其除了是 DNN 最常用的解释方法形式之外,它们还可能为各种类型的神经网络生成解释。局部可解释性方法确实广泛应用于 DNN 和其他类型的机器学习模型,因为它们可以深入了解模型如何做出特定决策。此外,一些局部可解释性方法被认为是与模型无关的,这意味着它们可以应用于各种不同类型的模型。然而,并非所有局部可解释性方法都是与模型无关的,还存在其他研究领域,例如特定于模型的可解释性。
Based on Stage
通过解释所在模型训练中的阶段进行划分,可以划分为两类:事前解释,既在训练之前分析黑盒模型的经典方法,以及事后解释,既在训练之后分析黑盒模型的方法。
Ante‑Hoc Interpretability
事前可解释性技术主要由传统的AI训练组成。此类技术的设计理念是保持简单的结构,以便将复杂性限制在一定范围内,因此被称为玻璃盒(glass box)技术。因此,事前可解释性与内在可解释性(intrinstic interpretability)密切相关。事前可解释性主要涉及处理数据本身,因为数据评估为需要解释的模型提供了必要的洞察力(insight)和理解(understanding)。以下是一些常用的可解释技术:
线性回归利用模型的输入特征之间的线性关系来解释其预测。
逻辑回归模型是线性回归的一种修改,用于解决具有两种可能结果的分类问题。
通过决策树的叶节点给出解释。
基于规则的学习器:此类模型制定规则以从其输入数据中表征数据。这些规则可以是 if-else 规则,也可以是一组更复杂的组合。基于模糊规则系统 (Fuzzy-rule-based, FRBS) 是基于规则的学习器模型,同时也基于模糊集。这些模型解决了涉及不确定性和不精确性的现实问题。在[32]中可以找到使用 FRBS 进行研究的解释。
K-NNs:这种方法是非参数化的,可以简单而有条理地对实例进行分类。在 XAI 中,KNN 可以被视为一种可解释的算法,因为它为其预测提供了清晰的解释。该解释基于以下原则:算法根据训练数据集中最近邻的类标签对新数据点进行分类[33]。这使得人们相对容易理解和验证预测背后的推理。然而,与其他更复杂的算法相比,KNN 可能并不总是能够提供最准确的预测。
Letham 等人[34]提出了一种称为贝叶斯规则列表 (Bayesian Rule Lists, BRL) 的模型,该模型基于[35]中提到的决策树。它能够挑选出某些数据模式,这些模式可用作生成决策列表的标准。初始模型产生了很好的结果,并且有改进的空间,可以在领域级别建立信任。
在输入特征之间存在线性关系的情况下,树的效率不高。它们也很容易受到攻击。根据上述逻辑函数[26],回归模型将线性模型的输出拟合在 0 和 1 之间,从而使权重的线性影响可以忽略不计。逻辑回归模型的主要缺点之一是,由于所考虑的权重具有乘法性质,因此其解释相对更具挑战性。
决策树用于克服特征中的非线性和相关性问题,线性回归模型无法对这些问题进行解释。决策树的功能是将输入数据连续分割成树的节点,每个节点代表属于数据集中特定样例的子集[36]。通过从根节点移动到树的特定部分,即使是训练数据集中最轻微的变化,也会提供不稳定的结果。
由于易于提供解释,事前可解释方法一直优于其他“黑箱”方法。然而,由于这种内在的可解释性,准确性会受到影响。准确性和可解释性之间这种不可行的权衡表明,事后解释应该被考虑进去。
Post‑Hoc Interpretability
与事前方法相反,事后可解释性是指涉及训练后黑盒模型的研究和开发的技术。事后方法的一个有趣特点是它们在 XAI 领域的应用多种多样,也扩展到内在可解释模型中的应用。例如,置换特征是一种事后解释方法,被用于决策树的计算。
1、Model‑Specific Methods
尽管特定于模型的可解释性方法很有用,但它们为不透明的 AI 算法预测的解释范围非常有限。因此,有限的选择性阻碍了它们被主流的 XAI 方法研究所接受。然而,它们的特殊性仍然能够被发掘出在可解释方面的作用,例如,在主导模型表示和预测的情况下,其得到了利用。为了应对其应用的有限性,研究人员提出了与模型无关的可解释性方法,这些方法独立于模型并提供有竞争力的结果。
2、Model‑Agnostic Methods
与模型无关的可解释性方法适用于不同类型的 ANN 和黑盒模型。它们的通用性是通过同时分析特征的输入和输出来实现的。但它们的结构定义限制了它们对于模型的洞察力,例如模型的权重和关键参数。
当前对于与模型无关的可解释方法的研究数量在逐步上升,以涵盖XAI的各个方面。因此,本文将此类方法分为了一下几类。
Visualisation 可视化
黑盒模型的可视化有助于我们深入研究算法的隐藏模式和内部推理,这会增强对其预测的理解。该技术的灵活表示有助于它在其他解释方法中脱颖而出。可视化应用最流行的领域之一是监督学习算法。一些流行的可视化技术包括:
部分依赖图 (Partial Dependence Plot, PDP) 使用基于图形的解释来可视化一个或多个特征(最多三个特征)与黑箱模型生成的预测之间的关系[37]。它具有全局性,不仅可以全面掌握模型解释,还可以相应地将目标特征关系区分为线性、单调性或复杂性。之后为了了解预测因子对条件平均处理结果(选民动员实验得出的)的关联效应,Green 和 Kern[38]以及Elith 等人[39]通过用 PDP 取代随机梯度提升来理解不同的环境因素如何影响淡水分布,并在实际应用中做出了重大贡献。一些学者认为,平均边际效应会隐藏它们与数据的相互作用,他们认为这对黑箱模型不利。因此,必须开发一种新的解释技术来解决这个问题。
个体条件期望 (Individual Conditional Expectation, ICE) 图是部分依赖图的扩展版本,它揭示了 PDP 隐藏的异质效应。它们可以被视为 PDP 的局部等效模型,因为它们通过可视化特征对所观测预测的指定实例的影响来进行解释。换句话说,PDP 是 ICE 图生成的所有结果线的集合。由于其对个体的强调,ICE 曲线自然比 PDP 图更全面。但ICE 曲线也存在一些严重的问题,既同时存在大量实例会造成过度拥挤,使图变得不清晰。Casalicchio 等人[40]。通过提出一种可以使用两种可视化工具来帮助使黑盒模型透明的方法,能够打破 PDP 和 ICE 之间的困境。此类工具的一个例子是“无损可视化方法(lossless visualisation methods)”,这些技术用于表示由 ML 模型生成的高维数据,同时保留数据中的所有信息。这些方法旨在提供清晰、易于解释的可视化,避免“准解释”问题,既这些解释看似有意义,但却基于误导性或不相关的特征。无损可视化方法的示例包括降维技术[41][42](例如 PCA 或 t-SNE)、散点图和热图。这些方法在确保数据中的信息不会丢失或扭曲,以及产生的解释有意义且准确方面发挥着重要作用。
累积局部效应 (Accumulated Local Effects, ALE) 由 Apley 和 Zhu[43]引入,ALE 图在可视化相关特征方面始终处于领先地位。虽然部分依赖性图会导致计算特征效果存在明显偏差,但 ALE 提供了一种更快、无偏差的可视化替代品[44][45]。现在,PDP 和 ALE 都具有将复杂预测函数简化为更简单的函数的能力,使得函数一次处理一个或两个特征。然而,它们的主要区别在于它们是利用预测平均值还是预测差异。ALE 采用后者并在网格上聚合它们。尽管 ALE 图的计算速度更快,但其本质上很复杂。上述可视化技术都无法成功解释具有强特征相关性的模型。但是,随着工作进展速度的加快,目前ALE 已达到最佳状态。
Example‑Based Explanations
基于样例的可解释性作为单独的一类方法,该方法使用模型训练数据集中的特定实例来阐述黑盒模型的预测。简单来说,他们的方法可以简化为“由于 A 等同于 B 并且 B 生成 C,因此 A 也将生成 C。”基于样例的方法作用于 ML 模型的特定实例,而与模型无关的可解释方法通过利用其特征或对其进行更改来解释模型。
从研究的角度来看,一些被广泛接受的基于示例的可解释性技术如下:
Prototypes and Criticisms
原型是一组经过选择的、能够准确描述所有数据的示例。为了改变模型的输出预测,必须选择对应原型无法很好表示的数据实例。这些方法基于这条理由:“如果某件事 X 以不同的方式完成,其效果 Y 也会有所不同。”原型是直接从数据中获取的代表性示例,而反事实可以通过组合新的输入实例来创建。但是,尽管反事实看起来多么人性化,但它们仍然具有某些缺点。在“罗生门效应”(Rashomon Effect)这种现象中,用户面对太多选项时往往会选择不充分的反事实解释,从而导致性能不佳。因此,它阻碍了用户充分利用反事实的潜力。Hasan 等人[46]意识到需要减轻这种影响,并提出了一种博弈论视角,使反事实更加有应用价值,他们成功地通过将其优化为更明智的过程来缩小反事实的可能性。
由于反事实解释不需要访问模型或数据集本身,因此它们提取解释的实现似乎符合所有者的最佳利益。因此,它们最近受到越来越多的公司的关注,这些公司提供解释而不干扰他们的模型和数据。
选择相应原型表示不佳的数据实例受到了惩罚(criticised)。它们可用于表征数据(独立)或根据它们的关系(依赖)解释黑盒模型。 根据审查的文献,有许多方法可以定位数据中的原型(例如 k-medoids 算法),但很少有方法可以定位惩罚。 本文使用谷歌图像分类器将黑人误认为大猩猩的例子来证明惩罚的存在有多么重要。 研究发现,将黑人的照片作为负样本会增加数据集的多样性[47]。 Kim 等人[48]提供了 MMD-critic,这是一个全新的框架,它提供了描述整个数据集所需的最佳原型和惩罚数量。
Counterfactuals
Wachter 等人[49]提出了反事实解释,以此来解释神秘的人工智能算法所做的预测和选择。反事实解释概述了对输入特征值的最小调整。
Adversarial
对抗性示例基本上是带有轻微扰动的实例,目的是欺骗 ML 模型。例如,攻击者能够通过在眼镜或帽子上引入各种图案来成功欺骗面部识别 AI 系统。借助对抗性示例,人们可以深入了解算法的内部结构,发现其漏洞并提高可解释性。
Szegedy 等人[50]提出了一种基于梯度的方法,可用于为 DNN 提供对抗性实例。Goodfellow 等人[51]开发了用于实现对抗性图像的快速梯度符号方法。Su 等人[52]演示了如何通过仅更改一个输入图像像素来欺骗图像分类器。Athalye 等人[53]通过创建 3D 打印的乌龟成功欺骗了 DNN,DNN 误以为它是武器。
但是这些欺骗工具如何帮助研究人工智能模型的可解释性?答案在于近期的一些研究,即建立“稳健”模型,以抵抗这种对抗性干扰并提供更高质量的解释。Ilyas 等人[54]根据特征的稳健性(即对抗对抗性示例的能力)对其进行分类,并证明稳健模型比非稳健模型具有更合理的解释。
Influential Instances
基于机器学习的方法根据对训练数据的学习来生成预测。即使训练实例中的一个小修改也可能显著改变最终模型。“有影响力的”训练实例是对模型的参数确定和决策产生重大影响的实例。这些有影响力的实例对于调试和检查模型的行为至关重要。寻找有影响力实例的方法之一称为删除诊断[55]。在此,我们只需删除相关实例,并分析有和没有该实例时模型预测的差异,以此来进行解释。
Methods For Visualising and Interpretation
数据可视化可以定义为使用数据创建图像的复杂算法,以便人类能够更有效地理解和响应。人工智能开发就是在寻找比人类更好、反应更快的算法。人工智能学习技术基于编写模型,但不是人类使用你的模型,而是系统将一些数据作为输入并创建一个新模型(图 4)。在 Tensor Flow 库或 Microsoft Azure ML Studio 等可视化工具的帮助下,探索性数据分析可以使事情变得合理。使用先进的数据处理软件,开发人员可以集成多个协调视图,无缝探索大规模深度学习模型并预测结果,以及发现模式。以下是人工智能软件可以用于数据可视化的一些新方法和新途径:
- 交互式可视化:使用动态、交互式可视化,让用户实时探索数据和模型行为
- 增强现实 (AR) 和虚拟现实 (VR) 可视化:使用 AR 和 VR 技术创建沉浸式可视化,帮助用户更好地理解和与数据交互。
- 3D 和 4D 可视化:使用 3D 和 4D 可视化以全新且更具信息量的方式呈现数据,让用户更好地理解复杂的关系和模式
- 自动可视化生成:使用机器学习算法根据数据和所需输出自动生成可视化。
- 实时流式可视化:创建可以在收到新数据时实时更新的可视化,让用户能够实时监控数据和模型性能。
- 多视图可视化:使用多个视图或视角来表示数据,允许用户从不同角度探索和理解数据。
随着向 AI 模型提供高质量数据的不断努力,开发人员越来越擅长可视化数据,而不仅仅是数字中隐藏的内容;这个概念在 AI 世界中具有重大意义。为了了解趋势和发现异常,呈现的数据可以帮助 AI 可视化并理解问题的背景。一些例子包括 DGMTracker 和 GANViz,它们专注于帮助开发人员了解训练动态并训练这些复杂的模型。该领域的研究包括创建各种工具和框架以实现民主化和互操作能力,但新的工作会立即开源,而无需在知名会议上发表。可能有很多语言可以执行数据可视化,但使用最广泛的是 Python 和 R。哪一种最好并且具有更好的范围?答案很简单;这纯粹是用户的选择。在本文中,我们的主要目标是理解概念,例如哪些条件最适合可视化概念,并深入研究编码/实现以帮助采样图。
数据解释是最新出现的创新之一,它将各个研究领域的技术和领域结合在一起。海量的数据随处可见,需要付出巨大的努力才能系统地组织所有数据。人类根本无法读取所有数据并对其进行组织。人工智能的重要性是真实存在的,不容忽视。在当今时代,有优秀性能的个人电脑,甚至连人类专家都被它们打败了。数据分析与人工智能一起,劳动密集程度更低,效率更高。人工智能自动化机器人是一种有用的软件,它通过机器学习收集知识,每天与数百万用户进行交互。它刺激了人类的互动,减少了工作量。它解释数据并将每个句子分解成单个单词,每个单词都用作 ANN 的数据。
另一个有助于解释数据的新兴主题是大数据。近年来,大数据在人工智能领域不断发展,并解决了几乎所有人类挑战。大数据是指传统数据处理软件无法捕获和处理的大量实例(也可能是特征)。通过大数据分析,欺诈检测、财务风险分析和价格优化等实时问题可以在几分之一秒内完成。可以注意到,为什么在麦当劳或卡乐星点的薯条总是准时的,并且有时也会提前一点?答案很简单,大数据可以监控顾客的数量,如果排队时间太长,它只会反映出那些可以快速准备的物品。在环球影城,他们给我们安装了RFID标签的腕带。整个公园安装了数千个传感器,收集有关活动的信息。因此,大数据有助于我们提升客户体验。一项调查显示,由于缺乏适当的维护,大数据也存在一些缺点。在任何时候,数据盗版和泄露的风险都很高,企业面临着网络攻击的潜在风险。此外,如今出现的一个主要问题是缺乏对大数据的认识。拥有技能并能处理大数据的人很少愿意从事大数据工作。
Evaluating the Quality of Explanations and Error Mitigation
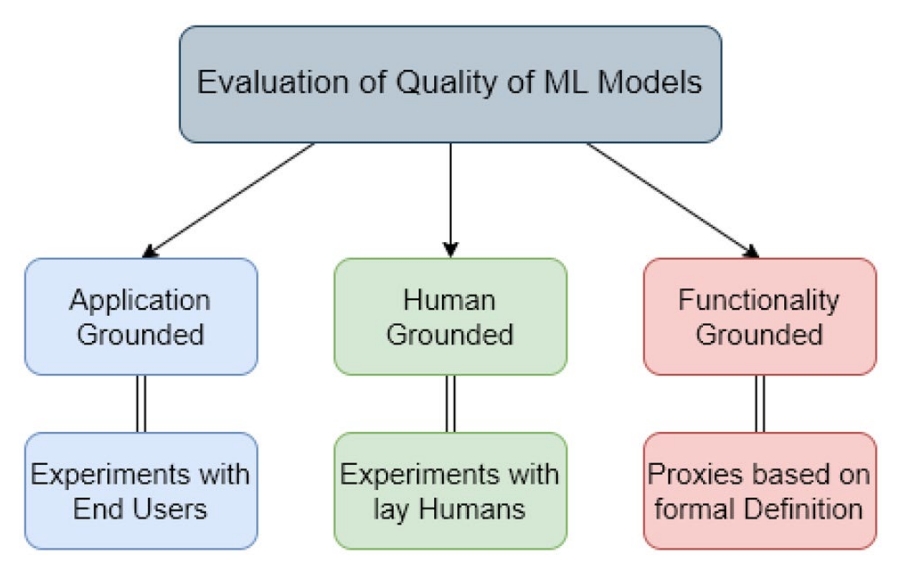
除了为 AI 决策提供解释外,还应考虑在该领域尚处于早期阶段时在 XAI 框架下采用评估方法。通过这样做,XAI 将能够满足更广泛的利益相关者的需求。然而,可解释性的主观性对研究人员来说是一个严峻的挑战。
衡量解释质量的一个基本原则是,评估是否证明了所声称的贡献。随后,其他因素(例如资源的最佳利用、最少的时间消耗和解释程度)也可能包含在基准过程中。Doshi-Velez 和 Kim[56]提供了一个范例,将评估技术分为以下几类(也如图 5 所示):
- 应用基础:该方法涉及领域专家在现实生活中进行实验以验证最终任务的交付。更具体地说,它承认任何新事实的发现、新错误的调试和偏见的消除。例如,为了诊断疾病,最合适的方法是让医生进行诊断[57]。
- 以人为本:这种方法涉及普通人类进行一般实验,以解决更广泛的评估概念。事实证明,这是一种保持目标应用核心的经济有效的方法。例如,人类可以在两种理论之间做出选择,他们需要选择准确率更高的理论[58]。
- 功能基础:该方法涉及评估可解释性的代理度量,因此需要进一步研究。无需人机交互和成本最低是其广泛使用的一些吸引人的因素。例如,决策树在许多情况下被认为是可解释的[59]。
Holzinger 等人[60]设计了因果性概念,后来他们将其与广泛接受的可用性量表相结合,形成了系统因果性量表 (SCS),SCS 衡量人工智能模型决策背后的某种解释与用户达成因果理解的程度。
通过 DL 进行错误缓解被称为用于减少量子计算算法中特定错误的简单技术。许多 XAI 方法都会生成显著性图。这些图突出显示并增加具有相似显著属性的特定图像的像素强度。尽管它取得了成功,但它的黑箱性质在医学和自动驾驶等关键领域是一个严重的障碍。如果这些图受到数据中毒或模型训练不足,它们就会失效。显著性图假设模型中的所有特征都是可解释的,但在某些情况下,模型可能会根据与人类不相干的特征做出决策。为了提高显著性图的准确性,Ismail 等人[61]采取了不同的方法,提出了一种称为显着性引导训练的新训练程序。此程序提供的输出噪声较少且清晰,并且不会降低模型的性能。
References
[21] Breiman L. Random forests[J]. Machine learning, 2001, 45: 5-32.
[25] Friedman J H, Popescu B E. Predictive learning via rule ensembles[J]. 2008.
[26] Molnar C. Interpretable machine learning[M] 2nd ed. Lulu. com, 2020.
[47] Olsson C. How to make your data and models interpretable by learning from cognitive science. 2017.
[50] Szegedy C. Intriguing properties of neural networks[J]. arXiv preprint arXiv:1312.6199, 2013.
感谢浏览,欢迎关注祁彧w博客!

文章评论