本文介绍了一种新的文本到图像生成模型(Text-Image Generative Models)的评估方法,其采用了VQA来衡量生成图像与其文本输入之间的忠实度,可以从更细粒度的层面评估文本图像生成模型的性能,例如颜色、数量以及组合关系。
Abstract
尽管成千上万的研究人员、工程师和艺术家积极致力于改进文本到图像生成模型,但系统通常无法生成与文本输入准确一致的图像。我们引入了 TIFA(带问答的文本到图像忠实度评估),这是一种自动评估指标,它通过视觉问答 (VQA) 来衡量生成的图像与其文本输入的忠实度。具体来说,给定一个文本输入,我们使用语言模型自动生成几个问答对。我们通过检查现有的 VQA 模型是否可以使用生成的图像回答这些问题来计算图像忠实度。TIFA 是一种无参考指标,可以对生成的图像进行细粒度和可解释的评估。与现有指标相比,TIFA 与人类判断的相关性也更好。基于这种方法,我们引入了 TIFA v1.0,这是一个基准,由 4K 个不同的文本输入和 12 个类别(对象、计数等)的 25K 个问题组成。我们使用 TIFA v1.0 对现有的文本到图像模型进行了全面评估,并强调了当前模型的局限性和挑战。例如,我们发现,尽管当前的文本转图像模型在颜色和材质方面表现良好,但在计数、空间关系和组合多个对象方面仍然存在困难。我们希望我们的基准测试能够帮助仔细衡量文本转图像合成的研究进展,并为进一步的研究提供有价值的见解。

TIFA 工作原理的说明,以及与广泛使用的 CLIPScore 和 SPICE 指标的比较。给定文本输入,TIFA 使用 GPT-3 生成几个问答对,然后 QA 模型对它们进行过滤(显示了此文本输入的 14 个问题中的 3 个)。TIFA 测量 VQA 模型是否可以在给定生成的图像的情况下准确回答这些问题。在此示例中,TIFA 表示 Stable Diffusion v2.1 生成的图像比 v1.5 生成的图像更好,而 CLIP 和 SPICE 得出相反的结果。文本输入来自 MSCOCO 验证集。
Introduction
当前扩散模型的一个关键的瓶颈是,缺乏可靠的自动评估指标来评估文本到图像生成忠实度。其中一个流行的指标是 CLIPScore[1],它测量文本输入和生成图像的 CLIP 嵌入[2] 之间的余弦相似度。然而,由于 CLIP 在计数对象[2]或组合推理[3] 方面效果不佳,CLIPScore 不可靠且通常不准确。另一类评估指标使用图像字幕,其中图像字幕模型首先将图像转换为文本,然后通过将其与文本输入进行比较来评估图像字幕。不幸的是,使用字幕模型是不充分的,因为它们可能会忽略图像中的显着信息或关注其他非必要的图像区域[4];例如,字幕模型可能会说图 1 中的图像是“一片草地,背景是树木”。此外,评估文本(标题)生成本身就具有挑战性[5][6]。另一个最近的文本到图像评估是 DALL-Eval[7],它使用对象检测来确定文本中的对象是否在生成的图像中。然而,这种方法只适用于合成文本,并沿着对象、计数、颜色和空间关系的有限轴测量忠实度,但错过了活动、地理位置、天气、时间、材料、形状、大小和我们在回忆记忆中的图像时经常询问的其他潜在类别 [8]。
因此,作者提出了TIFA方法,一种评估文本到图像生成忠诚度的新指标。
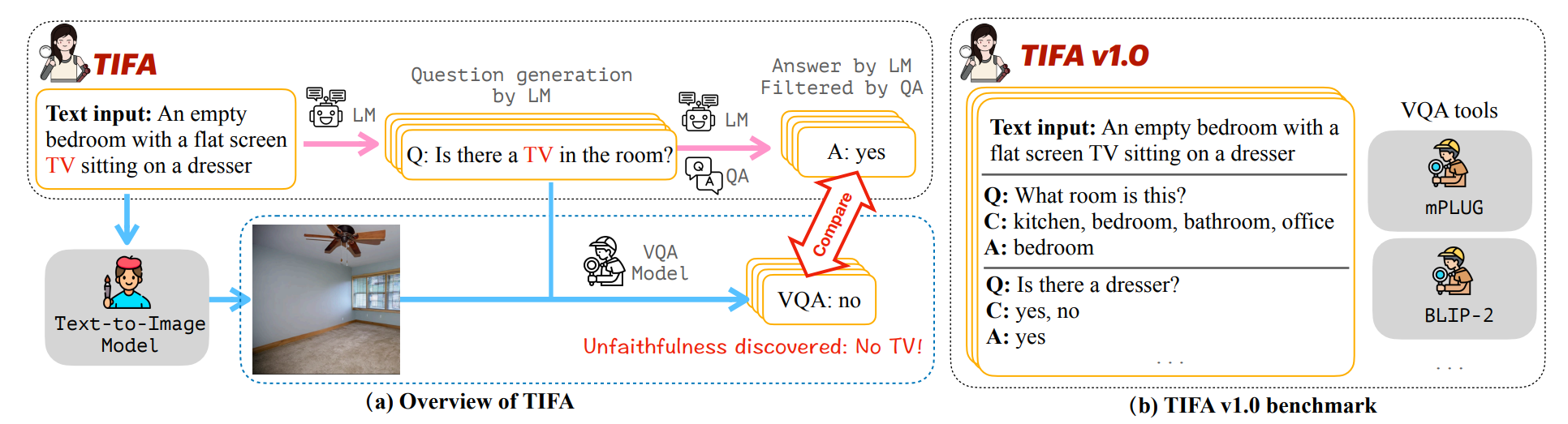
图 1. (a) Overview of how TIFA evaluates the faithfulness of a synthesized image. TIFA 使用语言模型 (LM)、问答 (QA) 模型和视觉问答 (VQA) 模型。给定一个文本输入,再使用 LM 生成几个问答对,然后通过 QA 模型对其进行过滤。为了评估合成图像对文本输入的忠实度,VQA 模型使用图像回答这些视觉问题,然后检查答案的正确性。 (b) TIFA v1.0 benchmark. 虽然 TIFA 适用于任何文本提示,但为了允许直接比较不同的研究,并为了易于使用,作者引入了 TIFA v1.0 基准,这是一个文本输入存储库以及带有答案选项的预生成的问答元组。为了评估文本到图像模型,用户首先在 TIFA v1.0 中为文本输入生成图像,然后使用提供的工具对生成的图像执行 VQA 以计算 TIFA。
根据图1,给定一个文本输入库,作者通过语言模型(此处为 GPT-3 [3])自动为每个文本生成问答对。随后使用问答 (QA) 系统(此处为 UnifiedQA[9])来验证和过滤这些问答对。为了评估生成的图像,作者使用视觉问答 (VQA) 系统(此处为 mPLUG large[10]、BLIP-2[11]等)来回答给定生成图像的问题。并将图像对文本输入的忠实度衡量为 VQA 系统生成的答案的准确性。虽然 TIFA 的准确性取决于 VQA 模型的准确性,但其实验表明,TIFA 与人类判断的相关性比 CLIPScore(Spearman's ρ = 0.60 vs. 0.33)和基于字幕的方法(Spearman's ρ = 0.60 vs. 0.34)高得多。此外,由于 LM 和 VQA 模型将继续改进,因此 TIFA 可以随着时间的推移将继续变得更加可靠。此外,作者提出的指标可以自动检测生成过程中何时缺少元素:在图 1 中,TIFA 检测到生成的图像不包含电视。
The TIFA Metric
作者引入了一个框架,用于自动评估图像与其文本提示的忠实度。给定一个文本输入 T,其目标是测量生成的图像 I 的忠实度。
根据输入文本 T,生成 N 个多项选择问答元组\(\{Q_i,C_i,A_i\}_{i=1}^N\),其中 \(Q_i\) 是一个问题,\(C_i\) 是一组答案选项,\(A_i\)是一个属于\(C_i\)集合的标准答案。给定 T、\(Q_i\) 和 \(C_i\),可以推断出答案 \(A_i\)。接下来,对于每个问题 \(Q_i\),作者使用 VQA 模型来生成答案 \(A_i^\text{VQA}=\max_{a\in C_i}p(a\mid I,Q_i)\)。并将文本 T 和图像 I 之间的忠实度定义为 VQA 准确率:
$$faithfulness(T,I)=\frac{1}{N}\sum_{i=1}^N\mathbb{1}[A_i^{\text{VQA}}=A_i]$$
忠诚度分数范围是 [0, 1]。当拥有一个高性能的 VQA 模型,并且图像 I 准确地覆盖文本 T 中的信息时,它就会最大化,因此,对于任何问题 Q,只要给定 T 就可以回答,给定 I 也可以回答。
Question-Answer Generation( how to generate questions)
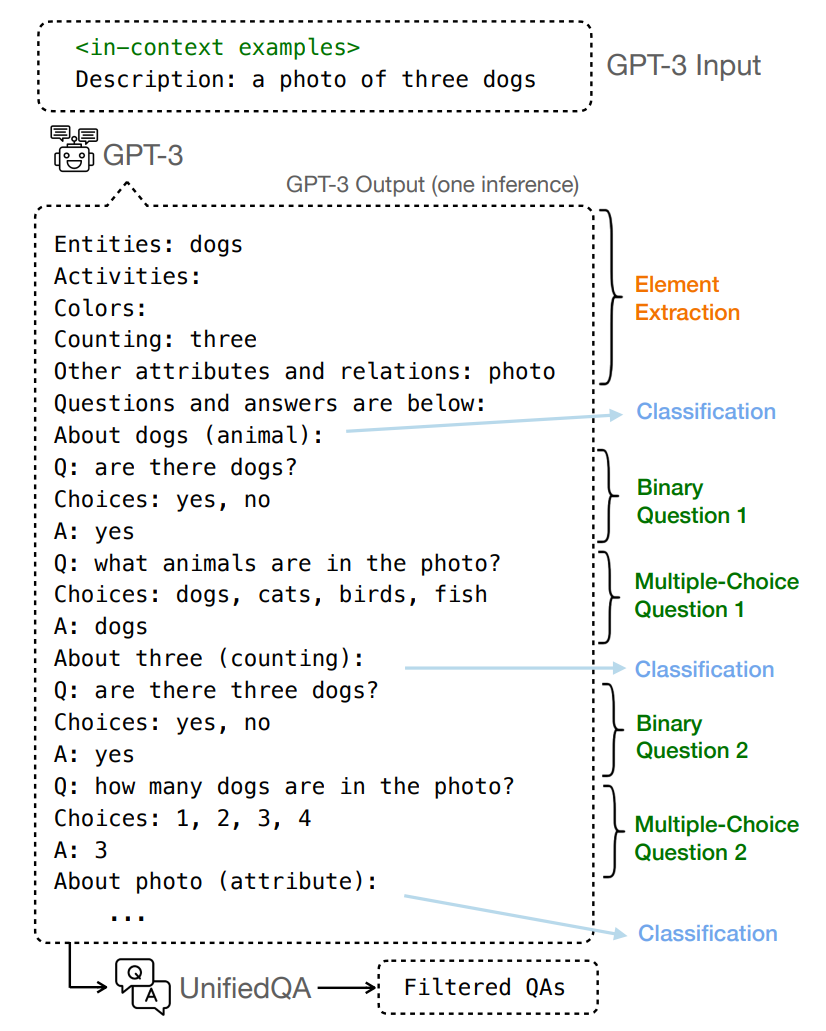
图 2. Our question-answer pair generation pipeline. 整个流程可以通过GPT-3单一推理的上下文学习来执行。给定文本提示,GPT-3 首先提取元素,然后为每个元素生成两个问题。然后由 UnifiedQA 解析和过滤 GPT-3 输出。
1、在这一部分,其主要挑战是生成多样化的问题,并均匀地覆盖文本输入的所有元素。
2、作者将问题生成流程简化为单个 GPT-3[12]完成,以便 TIFA 可以利用最新语言模型 (LM) 的强大功能,并在未来与更新的黑盒 LM(例如 ChatGPT)配合使用。
受先前研究[13]的启发,给定一个文本提示 T,作者通过图 2 所示的流程(pipeline)生成问答元组 \(\left\{Q_i,C_i,A_i\right\}_{i=1}^N\)。与依赖多个组件的先前研究不同,作者的流程通过使用 GPT-3 的上下文学习进行一次推理运行即可完成,从而避免了中间人工注释的需要。作者注释了 15 个示例,并将它们用作 GPT-3 遵循的上下文示例。这里以文本“A photo of three dogs.”为例。每个上下文示例包含以下步骤:
Element extraction 元素提取
给定文本提示 T,GPT-3 将首先提取所有元素 \(\begin{Bmatrix}\upsilon_i\end{Bmatrix}_{i=1}^m\),这遵循先前的工作 [4](对于上下文示例,作者手动执行元素提取)。这些元素包括名词短语(包括命名实体)、动词、形容词、副词和总共不超过 3 个单词的解析树跨度。对于上述示例,元素是 photo、three、dogs。
Element category classification 元素类别分类
对于每个元素 \(v_i\),其按照[8]将元素分为以下 12 个类别之一:物体、活动、动物、食物、计数、颜色、材料、空间、位置、形状、属性和其他。如图 2 所示,GPT-3 生成的文本包含与每个问题相对应的类别。例如,“three” 是“计数”,而“dogs” 被归类为“动物”。此步骤可以详细分析文本到图像模型在每个类别中的能力。
Question generation conditioned on elements 根据元素生成问题
对于每个元素 \(v_i\),其生成两个问题。第一个问题对于忠实生成的图像应该回答“是”,第二个问题的答案是 \(v_i\)。例如,对于元素“three”,生成两个问题。第一个是“有三只狗吗?”,选项是 {是,否}。第二个是“有多少只狗?”,选项是 {1,2,3,4}。这两类问题使我们的评估多样化,并且对表面差异具有鲁棒性
Completing above steps by prompting GPT-3 once 通过提示 GPT-3 一次完成上述步骤
如前所述,对于每个文本 T,整个流程可以通过一次 GPT-3 推理完成。作者注释了 15 个上下文示例,涵盖了所有类型的问题。完整prompt在附录中。提示格式如图 2 所示。其上下文示例遵循相同的格式,并且所有文本输入都使用相同的示例,从而使得人工注释成本固定且有限。作者使用 code-davinci-002 引擎生成问题,解码temperature为 0。
Question Filtering(how to control the question quality)
为了确保生成图像的质量,作者使用 UnifiedQA[9]来验证 GPT-3 生成的问答对,并过滤掉 GPT-3 和 UnifiedQA 不一致的问答对。UnifiedQA2 是一种最先进的多任务问答模型,可以回答多项选择题和自由形式的问题。将 UnifiedQA 模型表示为 QA。给定文本 T、问题 \(Q_i\)、选项 \(C_i\) 和答案 \(A_i\),让 \(A_i^f=QA(T,Q_i)\)) 为自由形式答案,\(A_i^{mc}=QA(T,Q_i,C_i)\) 为多项选择答案。如果 \(A_i=A_i^{mc}\) 并且 \(A_i^f\) 和 \(A_i\) 之间的单词级 \(F_1\) 得分大于 0.7,则保留问题。作者对 1000 个过滤后的问答对进行人工评估。只有 7 个被认为不合理(例如,生成的选项不包含正确答案)。详情请参阅附录 C。
VQA Models(how to answer those questions)
由于生成图像包含多种视觉元素(例如活动、艺术风格),作者使用开放预训练的视觉语言模型作其 VQA 模型(而不是在 VQAv2[14]上微调的封闭类分类模型)。作者基于使用不同数据和策略训练的 5 种最先进的 VQA 模型,提供了可轻松对任意图像和问题执行 VQA 的工具。
Vision-language models
通用的预训练视觉语言模型有 GIT-large[15]、VILT-B/32[16]、OFA large[17] 和 mPLUG-large[10]。这些模型在大量图像-文本对以及下游图像到文本任务(如图像字幕和视觉问答)上进行了预训练。请注意,这些模型尚未接受过回答多项选择题的训练。对于每个问题,作者首先解码自由形式的答案,然后选择与解码后的答案相似度最高的选项,以 SBERT[18]为衡量标准。作者使用的另一个模型是 BLIP-2 FlanT5-XL[11],其中 VIT[19]通过轻量级转换器与冻结的 FlanT5[20]相连。由于 LM 的灵活性,该模型允许直接执行多项选择 VQA。
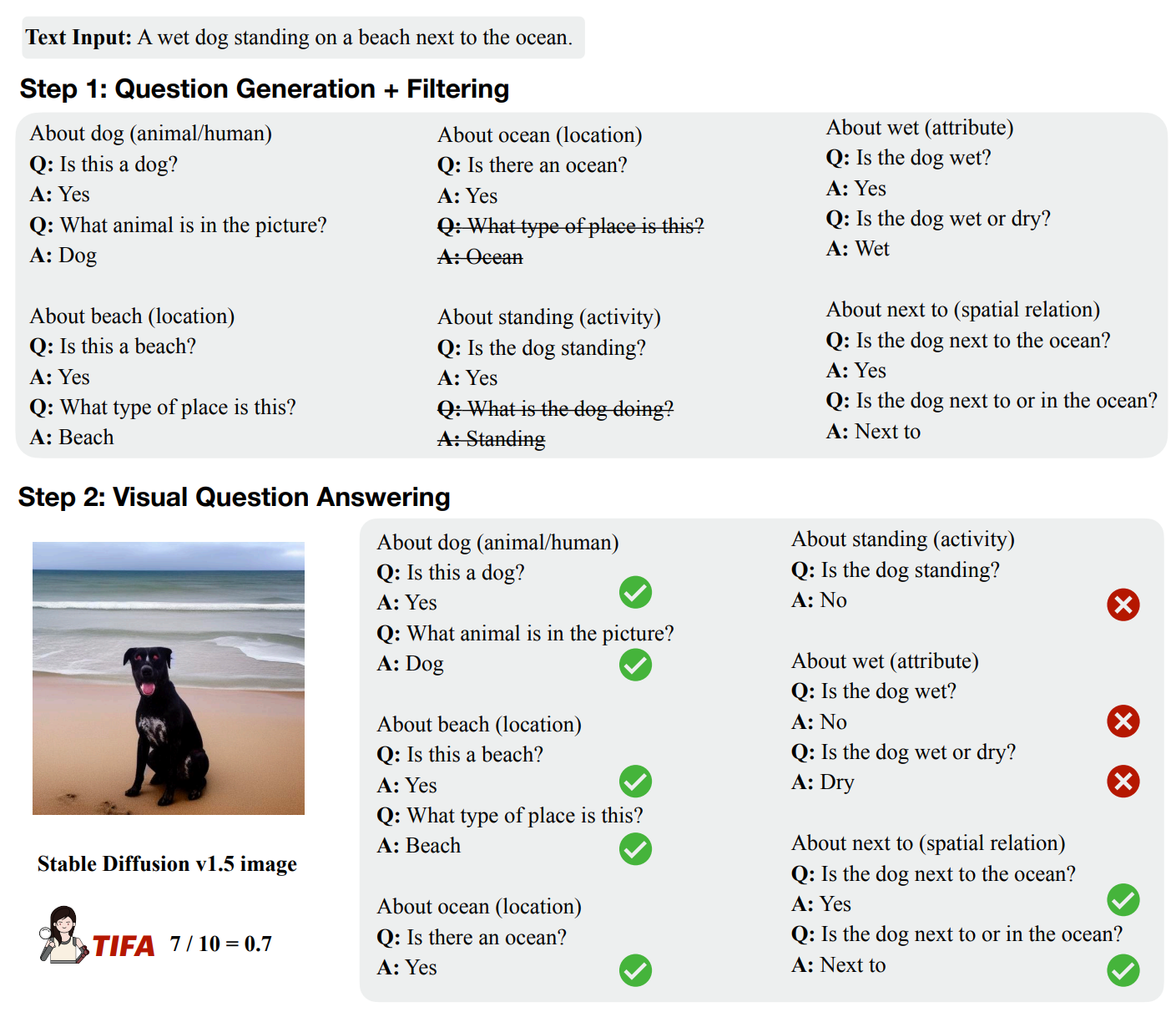
图 3. Step-by-step qualitative example of TIFA metric. 给定一个文本输入,首先生成问答对并对其进行过滤(删除 UnifiedQA 过滤掉的问题)。然后在生成的图像上运行 VQA 模型以获得 TIFA 分数。
最终,在图 3 中给出了 TIFA 的逐步定性示例。
Experiments
Correlation with Human Judgements
作者将其与两类无参考文本图像匹配指标进行比较。第一种是基于caption的方法。使用了最先进的 BLIP-2 FlanT5-XL[11]作为caption模型。第二种方法是 CLIPScore。使用了 CLIP (VIT-B/32) 来计算分数。
| Spearman's ρ | Kendall's τ | |
|---|---|---|
| Caption-Based | ||
| BLEU-4 | 18.3 | 18.8 |
| ROUGE-L | 32.9 | 24.5 |
| METEOR | 34.0 | 27.4 |
| SPICE | 32.8 | 23.2 |
| CLIPScore | 33.2 | 23.1 |
| Ours | ||
| TIFA(VILT) | 49.3 | 38.2 |
| TIFA(OFA) | 49.6 | 37.2 |
| TIFA(GIT) | 54.5 | 42.6 |
| TIFA(BLIP-2) | 55.9 | 43.6 |
| TIFA(mPLUG) | 59.7 | 47.2 |
表 1. 各评估指标与人类对文本到图像忠实度的判断之间的相关性,以 Spearman's ρ 和 Kendall's τ 衡量。
TIFA 与人类判断的相关性比之前的指标高得多。表 1 显示了每个评估指标与人类判断之间的相关性。对于基于caption的评估,使用了指标 BLEU-4[21]、ROUGE-L[22]、METEOR[23]和 SPICE[24]。在所有 VQA 模型中,TIFA 与人类判断的相关性比之前的所有评估指标都要高。在所有 VQA 模型中,TIFA (mPLUG) 与人类判断的相关性最高。
Benchmarking Text-to-Image Models
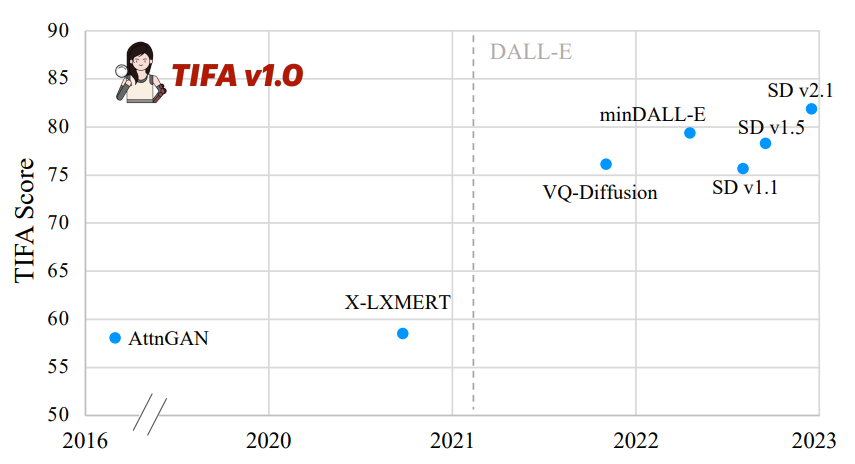
图 4. Average TIFA score of text-to-image models on the TIFA v1.0 benchmark. 横轴显示它们的发布日期。
图 4 显示了文本转图像模型在 TIFA v1.0 上获得的平均 TIFA 分数。附录 B 提供了每个 VQA 模型在每个元素类型上的详细分数。可以看到文本转图像模型随时间演变的明显趋势。DALL-E[25]发布后,TIFA 得分从约 60% 跃升至 75%。作者的评估指标的定性示例在附录 A 中。
Findings on Current Text-to-Image Models
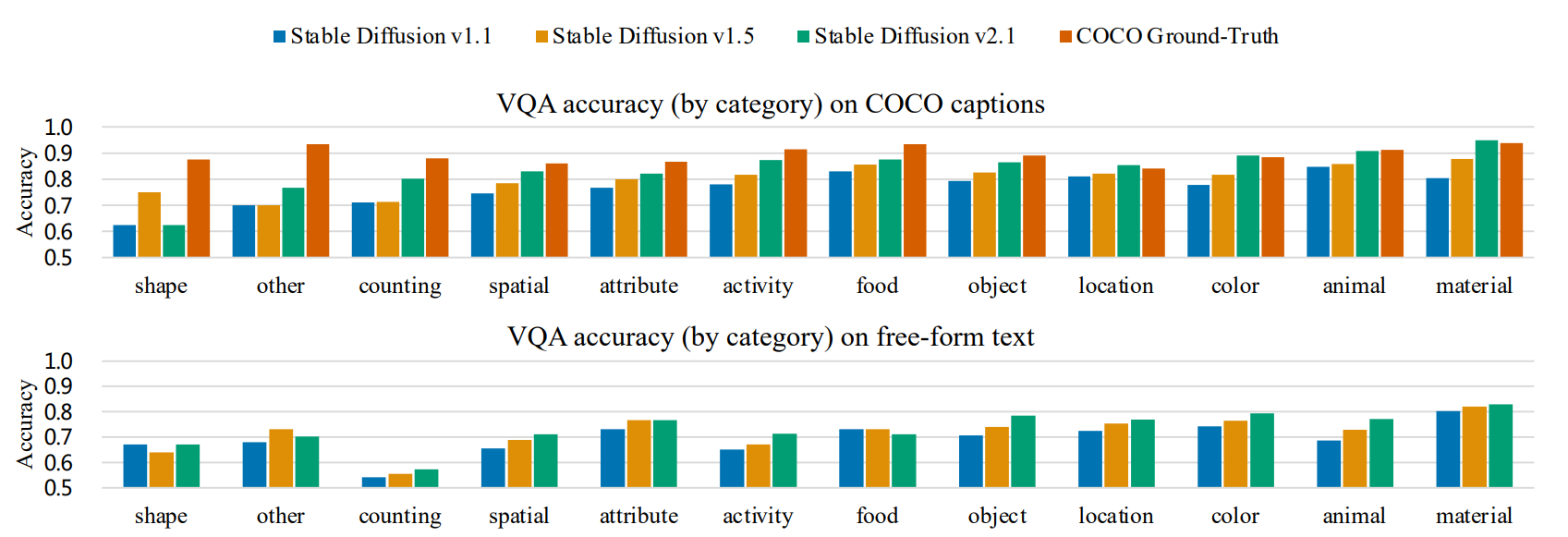
图 5. Accuracy on each type of question in the TIFA v1.0 benchmark. 文本转图像模型为 Stable Diffusion v1.1、v1.5 和 v2.1。作者按 Stable Diffusion v2.1 在相应问题上获得的平均分数对类别进行排序。对于 COCO captions,还包含了真实图像的准确率以供参考
图 5 显示了 TIFA v1.0 中 Stable Diffusion v1.1、v1.5 和 v2.1 中每种问题类型的准确率。每种类型的得分反映了文本到图像模型对每种视觉元素的忠实度。据作者所述,TIFA 是唯一能够提供如此详细的图像生成细粒度分析的自动评估方法。作者将 COCO captions和其他文本输入的得分分开。对于 COCO captions,作者还包括真实图像的准确率以供参考。
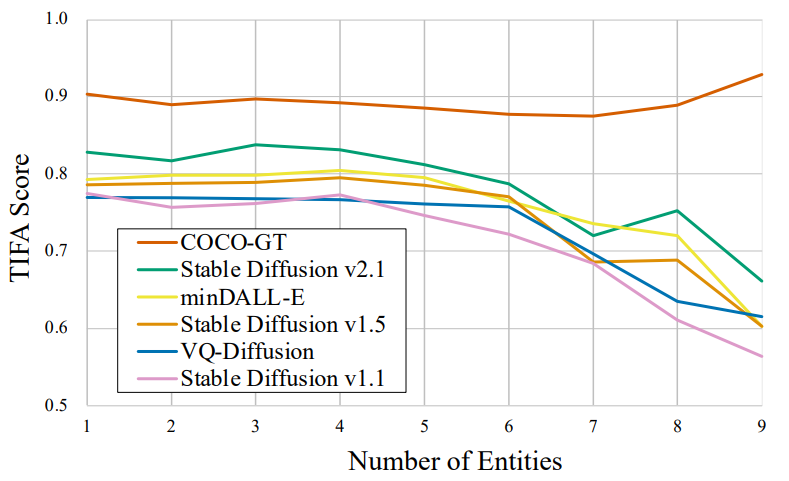
图 6. TIFA vs. numbers of entities (objects, animals/humans, and food) in the text input. 当文本中添加超过 5 个实体时,准确率开始下降,这表明文本到图像模型很难实现组合性。同时,COCO 真实图像 (GT) 的 TIFA 得分保持一致
图 6 显示了文本输入中的实体(对象、动物/人类、食物)数量如何影响平均 TIFA 分数。当实体超过 5 个时,所有文本到图像模型的 TIFA 分数开始迅速下降,这与其他视觉语言评估中的类似发现一致[26][27]。作为参考,作者还在此图中添加了 COCO 中的真实图像。真实图像上的 TIFA 分数相当一致,并且不会随着实体数量的增加而改变。这定量表明,对于当前的文本到图像模型来说,组合多个对象具有挑战性。一个可能的原因是,用于训练稳定扩散的 CLIP 文本嵌入缺乏组合性,如[3]中所述。
Analysis of VQA Models
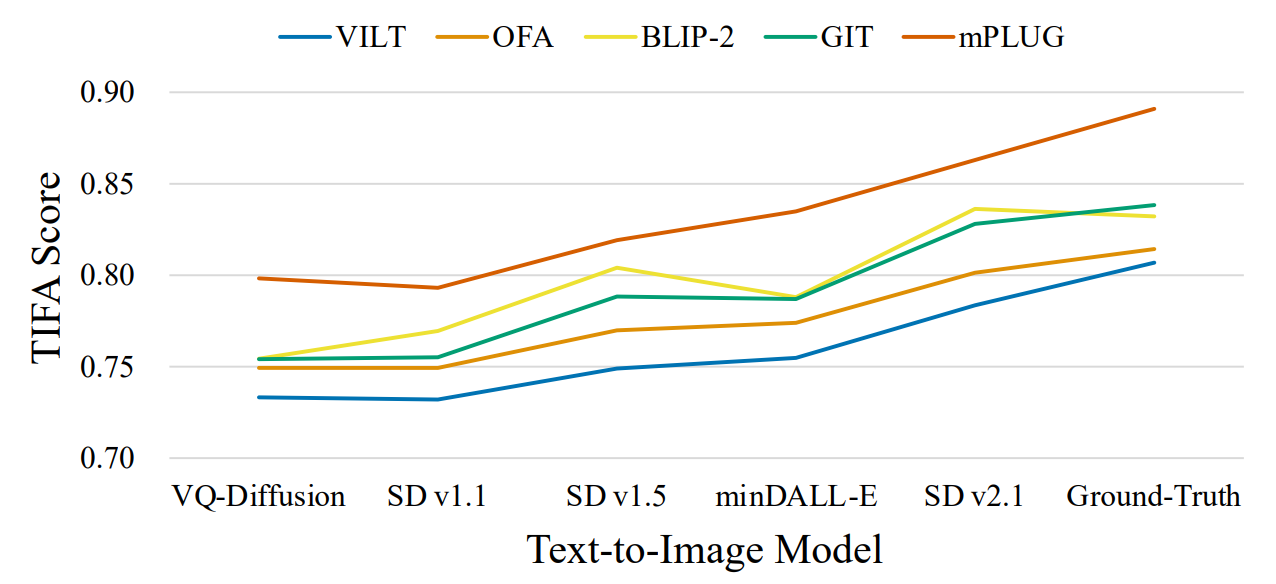
图 7. Several text-to-image models’ TIFA score on COCO captions, measured by different VQA models. 其中还包含了真实图像的准确率以供参考
图 7 显示了几个最近的文本转图像模型在 TIFA v1.0 中的 COCO captions上的 TIFA 分数,由不同的 VQA 模型测量。其还包括了真实 COCO 图像上的 TIFA 分数以供参考。由不同的 VQA 模型计算的 TIFA 分数在这些文本转图像模型上显示出相似的趋势。此外,真实图像获得最高的 TIFA 分数。之后还计算了不同 VQA 模型给出的 TIFA 分数的 Spearman's ρ 。所有 VQA 模型之间的成对相关性均大于 0.6。
| VILT | OFA | GIT | BLIP-2 | mPLUG | |
|---|---|---|---|---|---|
| VQA Acc. | 76.1 | 77.1 | 79.1 | 81.0 | 84.5 |
| TIFA Corr. | 60.9 | 63.7 | 72.5 | 75.6 | 76.8 |
表 2. Comparison of VQA models. 第一行是 VQA 准确率,以人类 VQA 答案为参考。第二行是每个 VQA 模型计算的 TIFA 分数与人类 VQA 之间的 Spearman 相关性。
表 2 报告了每个 VQA 模型的准确率以及 VQA 模型答案计算出的 TIFA 分数与人类答案之间的相关性。我们观察到,更高的模型性能与 TIFA 分数与人类判断的相关性直接相关。mPLUG 的准确率最高。
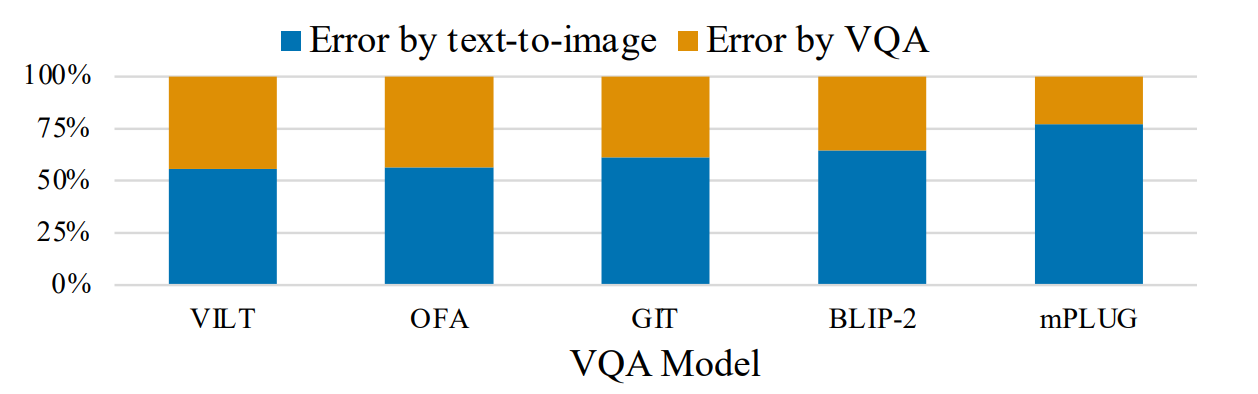
图 8. Source of the error when VQA gets the wrong answer.
假设在给定视觉问题的情况下,图像得到了错误的答案。那么图像生成或 VQA 模型可能会出错。根据人类 VQA 结果,作者在图 8 中将这两种错误分开。如果人类 VQA 给出了错误的答案,那么怀疑生成的图像有错误。否则,图像是正确的,但 VQA 模型出错了。图 8 显示,大多数错误是由文本到图像模型造成的。对于 mPLUG,不到 25% 的错误是由于 VQA 模型造成的。这表明,尽管 TIFA 框架存在固有的挑战,但它是一种可行的评估方法。
[12] Brown T B. Language models are few-shot learners[J]. arXiv preprint arXiv:2005.14165, 2020.
感谢浏览,欢迎关注祁彧w博客!

文章评论