简介
操作题:使用scikit-learn模块,并利用鸢尾花数据实现数据加载、标准化处理、构建聚类模型并训练、聚类效果可视化展示及对模型进行评价
数据预处理
数据加载
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split data = load_iris() train_data, test_data, train_target, test_target = train_test_split(data['data'], data['target'], test_size=0.2)
使用scikit-learn模块,从sklearn.datasets中导入鸢尾花数据,并赋值给data,其中iris的key包括了['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename']
同时使用train_test_split对数据集进行拆分。
train_test_split具有以下参数:
| 参数名称 | 说明 |
|---|---|
| *arrays | 接收一个或多个数据集。代表需要划分的数据集,若为分类回归则分别传入数据和标签,若为聚类则传入数据。无默认。 |
| test_size | 接收float,int,None类型的数据。代表测试集的大小。如果传入的为float类型的数据则需要限定在0-1之间,代表测试集在总数中的占比;如果传入为int类型的数据,则表示测试集记录的绝对数目。该参数与train_size可以只传入一个。在0.21版本前,若test_size和train_size均为默认则testsize为25%。 |
| train_size | 接收float,int,None类型的数据。代表训练集的大小。该参数与test_size可以只传入一个 |
| random_state | 接收int。代表随机种子编号,相同随机种子编号产生相同的随机结果,不同的随机种子编号产生不同的随机结果。默认为None。 |
| shuffle | 接收boolean。代表是否进行有放回抽样。若该参数取值为True则stratify参数必须不能为空。 |
| stratify | 接收array或者None。如果不为None,则使用传入的标签进行分层抽样。 |
标准化处理
from sklearn.preprocessing import StandardScaler model = StandardScaler().fit(train_data) train_data_mt = model.transform(train_data) test_data_mt = model.transform(test_data)
之后使用scikit-learn模块,从sklearn.preprocessing中导入StandardScaler对特征值进行标准差标准化处理
关于sklearn.preprocessing中的几个标准化处理方法
| 函数名称 | 说明 |
|---|---|
| MinMaxScaler | 对特征进行离差标准化处理。 |
| StandardScaler | 对特征进行标准差标准化处理。 |
| Normalizer | 对特征进行归一化。 |
| Binarizer | 对定量特征进行二值化处理。 |
| OneHotEncoder | 对定性特征进行独热编码处理。 |
| FunctionTransformer | 对特征进行自定义函数变换。 |
使用sklearn中的transform方法分别对训练集及测试集进行标准化处理。
实验及分析
构建聚类模型并训练
from sklearn.cluster import SpectralClustering model = SpectralClustering(n_clusters=3).fit(train_data_mt)
从sklearn.cluster中导入SpectralClustering聚类方法
其中cluster包含了以下几种聚类方法:
| 函数名称 | 参数 | 适用范围 | 距离度量 |
|---|---|---|---|
| KMeans | 簇数 | 可用于样本数目大,聚类数目中等的场景 | 点之间的距离 |
| SpectralClustering | 簇数 | 可用于样本数目中等,聚类数目较小的场景 | 图距离 |
| WardHierarchicalClustering | 簇数 | 可用于样本数目较大,聚类数目较大的场景 | 点之间的距离 |
| AgglomerativeClustering | 簇数,链接类型,距离 | 可用于样本数目较大,聚类数目较大的场景 | 任意成对点线图间的距离 |
| DBSCAN | 半径大小,最低成员数目 | 可用于样本数目很大,聚类数目中等的场景 | 最近的点之间的距离 |
| Birch | 分支因子,阈值,可选全局集群 | 可用于样本数目很大,聚类数目较大的场景 | 点之间的欧式距离 |
其中 n_clusters=3 表示了将簇数设置为3
聚类效果可视化
import matplotlib.pyplot as plt
for i in range(3):
plt.scatter(train_data_mt[model.labels_ == i, 0], train_data_mt[model.labels_ == i, 1])
plt.show()
使用matplotlib作散点图
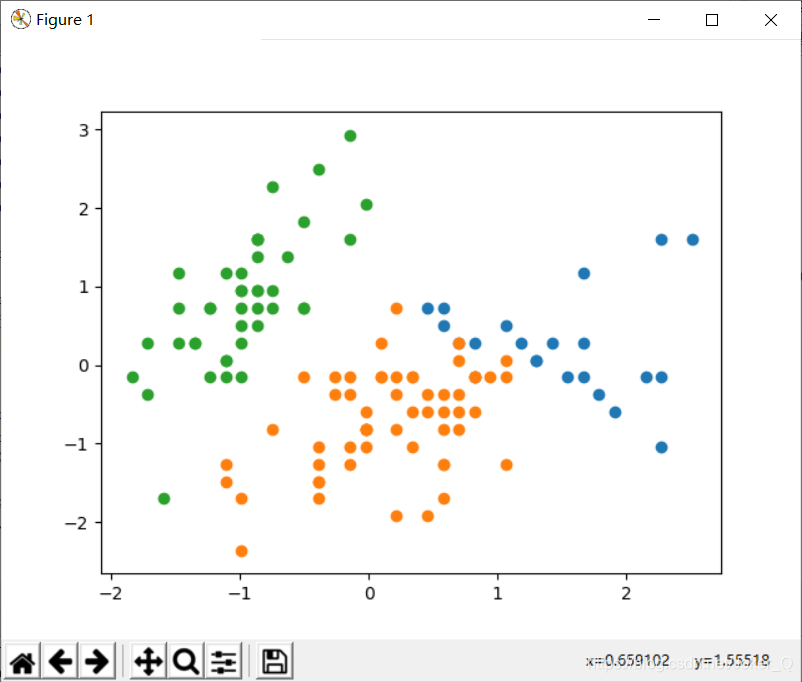
可以对数据进行降维处理,然后进行可视化。
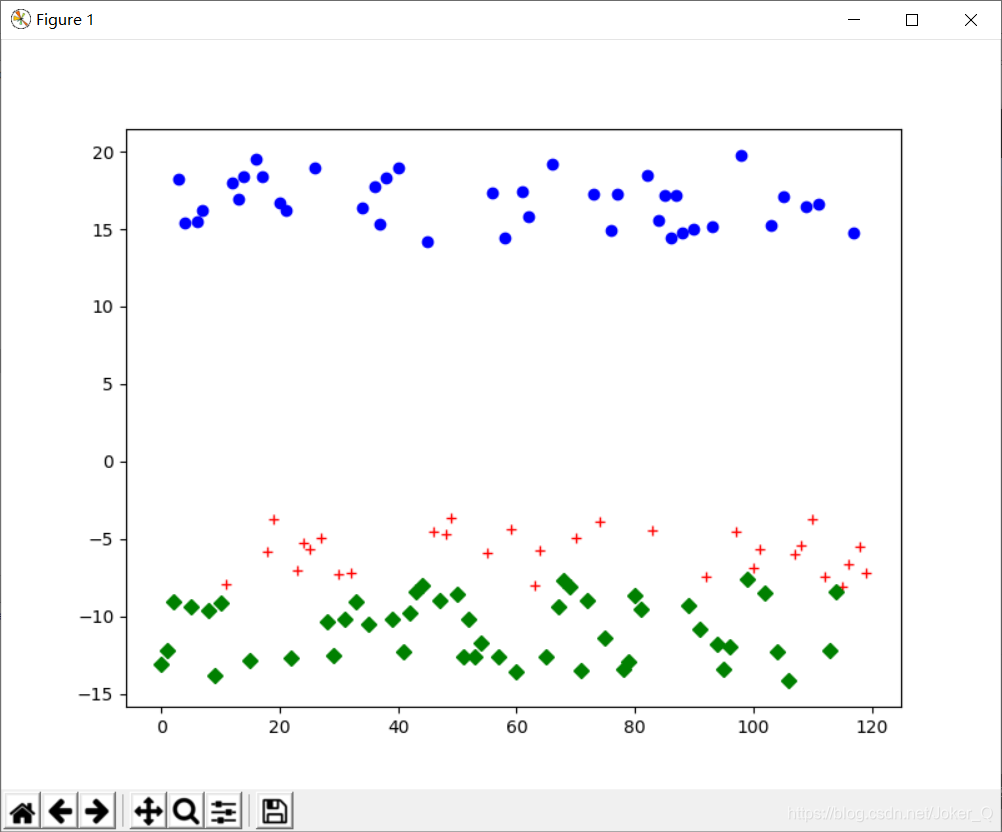
from sklearn.manifold import TSNE tsen = TSNE(n_components=2, init='random', random_state=123).fit(train_data_mt) # 降维 df = pd.DataFrame(tsen.embedding_) df['label'] = model.labels_ df1 = df[df['label']==0] df2 = df[df['label']==1] df3 = df[df['label']==2] fig = plt.figure(figsize=(8,6)) plt.plot(df1[0],'r+', df2[0], 'bo', df3[0], 'gD')
降维处理后的可视化效果
对模型进行评价
from sklearn.metrics import silhouette_score
for i in range(3,6):
model = SpectralClustering(n_clusters=i).fit(train_data_mt)
score = silhouette_score(train_data_mt, model.labels_)
print("当k =",i,"时,score =",score)
从sklearn.metrics中导入silhouette_score方法对模型进行评价
其中sklearn.metrics包括了以下几种评价方法:
| 方法名称 | 真实值 | 最佳值 | sklearn函数 |
|---|---|---|---|
| ARI评价法(兰德系数) | 需要 | 1.0 | adjusted_rand_score |
| AMI评价法(互信息) | 需要 | 1.0 | adjusted_mutual_info_score |
| V-measure评分 | 需要 | 1.0 | completeness_score |
| FMI评价法 | 需要 | 1.0 | fowlkes_mallows_score |
| 轮廓系数评价法 | 不需要 | 畸变程度最大 | silhouette_score |
| Calinski-Harabasz指数评价法 | 不需要 | 相较最大 | calinski_harabaz_score |
代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.cluster import SpectralClustering
from sklearn.metrics import silhouette_score
import numpy as np
import matplotlib.pyplot as plt
# 数据加载
data = load_iris()
print(data.keys())
train_data, test_data, train_target, test_target = train_test_split(data['data'], data['target'], test_size=0.2)
print(train_data.shape)
# 标准化模型(标准差标准化)
model = StandardScaler().fit(train_data)
train_data_mt = model.transform(train_data)
test_data_mt = model.transform(test_data)
print(np.max(train_data_mt), np.min(train_data_mt))
print(np.max(test_data_mt), np.min(test_data_mt))
# 构建聚类模型并训练(SpectralClustering)
model = SpectralClustering(n_clusters=3).fit(train_data_mt)
# 聚类效果可视化
for i in range(3):
plt.scatter(train_data_mt[model.labels_ == i, 0], train_data_mt[model.labels_ == i, 1])
plt.show()
# 评价聚类模型(轮廓系数评价法)
for i in range(3,6):
model = SpectralClustering(n_clusters=i).fit(train_data_mt)
score = silhouette_score(train_data_mt, model.labels_)
print("当k =",i,"时,score =",score)
博客CSDN链接:作业1:关于使用python中scikit-learn(sklearn)模块,实现鸢尾花(iris)相关数据操作(数据加载、标准化处理、构建聚类模型并训练、可视化、评价模型)
感谢浏览,欢迎关注祁彧w博客!

文章评论