
本文介绍了一种新的文本到图像生成模型(Text-Image Generative Models)的评估方法,其采用了VQA来衡量生成图像与其文本输入之间的忠实度,可以从更细粒度的层面评估文本图像生成模型的性能,例如颜色、数量以及组合关系。 Abstract 尽管成千上万的研究人员、工程师和艺术家积极致力于改进文本到图像生成模型,但系统通常无法生成与文本输入准确一致的图像。我们引入了 TIFA(带问答的文本到图像忠实度评估),这是一种自动评估指标,它通过视觉问答 (VQA) 来衡量生成的图像与其文本输入的忠实度。具体…
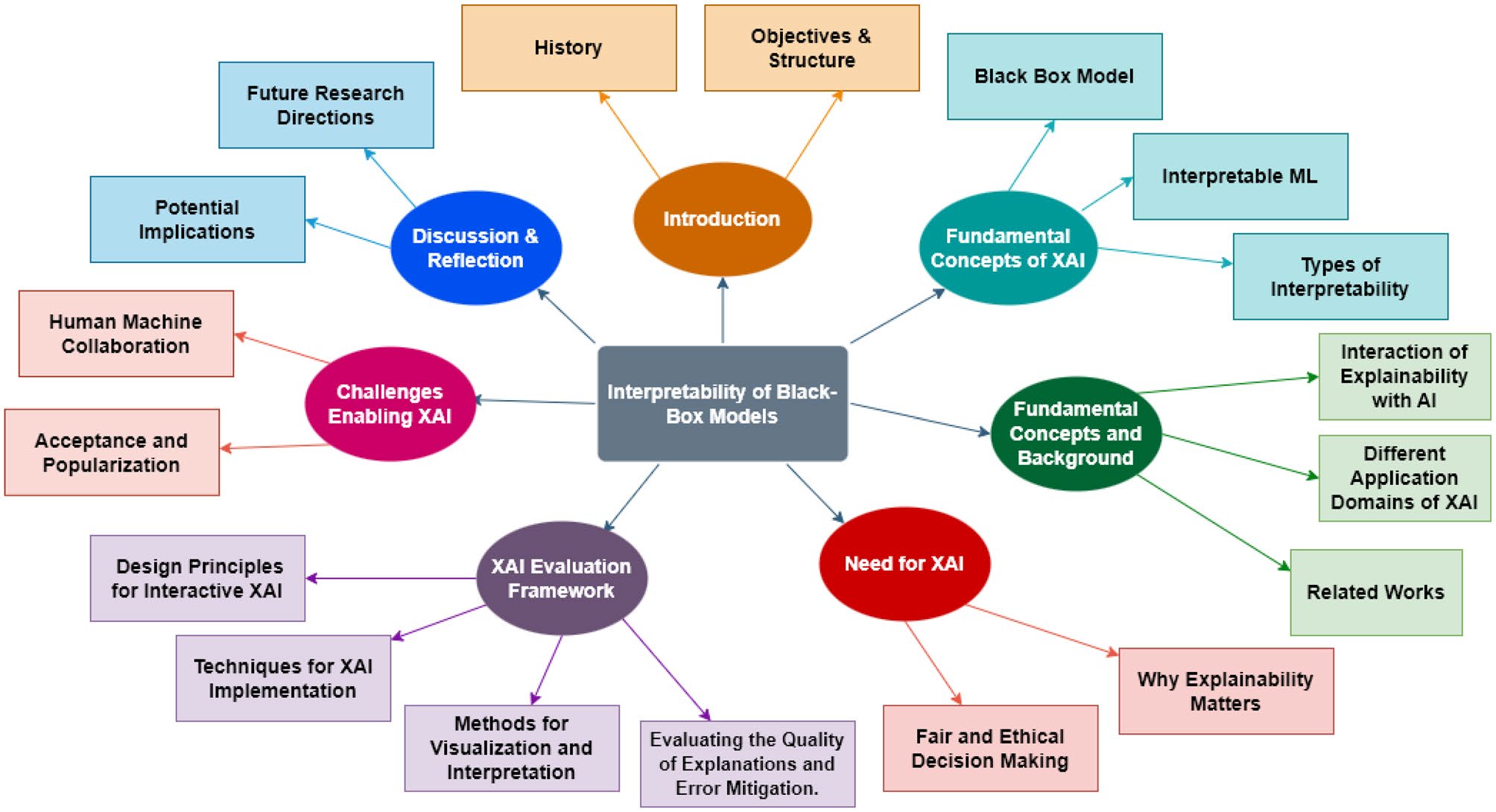
本文总结了 XAI 人工智能可解释性综述文章“Interpreting Black‑Box Models: A Review on Explainable Artificial Intelligenc”,包括XAI相关概念、XAI需要什么、XAI框架以及可解释验证方法。 Abstract 当前大多数机器学习(Machine Learning, ML)模型和深度学习(Deep Learning, DL)模型由于其结构复杂缺乏对决策过程的可解释,导致这些模型被称为“Black-Box”。而这些模型当被用于某些关键领域时…
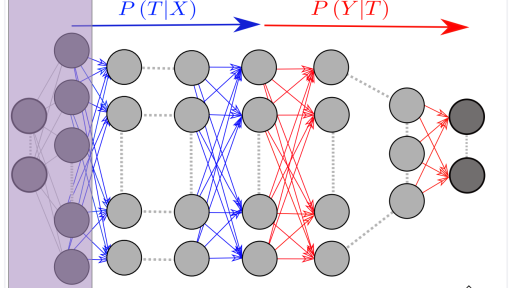
Opening the black box of Deep Neural Networks via Information Ravid Schwartz-Ziv, Naftali Tishby 本文部分内容待优化重写 引言 互信息(Mutual Information):是信息论里一种有用的信息度量,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性,由表示。 如上图所示,是一个完整的DNN内部层关于输入X的马尔科夫链。其中,任何一个输入的表示T,…
最近评论
祁彧w 发布于 2 年前(07月11日)